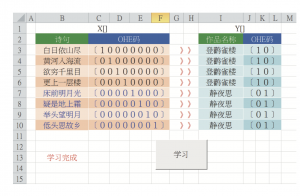
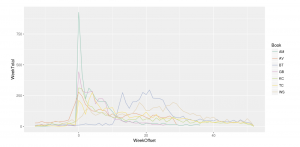
授权专栏, 数据与数据库, 文学 Reading Chicago Reading: Quantitative Analysis of a Repeating Literary Program 本文为过去二十年来规模最大、运行时间最长的大众阅读项目之一——由芝加哥公共图书馆(CPL)赞助的“一本书一个芝加哥”(OBOC)——提供了定量捕捉和预测模型。 公共图书馆, 大众阅读, 数据分析, 芝加哥
基础设施, 授权专栏, 数据与数据库 Open Data in Cultural Heritage Institutions: Can We Be Better Than Data Brokers? 本文将文化机构的收藏作为数据来对待,鼓励采用新的方法来使用历史收藏。 历史收藏, 开放数据, 数字经理人, 数据库, 文化遗产
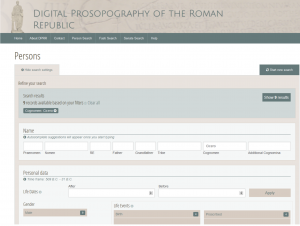
基础设施, 授权专栏, 数据与数据库 A Prosopography as Linked Open Data: Some Implications from DPRR 这篇文章解释了通过工作的、交互式的例子将材料呈现为链接开放数据的含义。 数据库, 罗马共和国, 群体传记, 链接开放数据
基础设施, 授权专栏, 数据与数据库 Crowdsourcing Image Extraction and Annotation: Software Development and Case Study 我们描述了基于网络的软件的开发过程,该软件有助于在数字人文学科感兴趣的以图像为主的语料库中进行大规模的、众包的图像提取和注释。 众包, 图像注释, 数据库, 软件开发
基础设施, 授权专栏 Editorializing the Greek Anthology: The palatin manuscript as a collective imaginary 希腊警句集(The Palatine Anthology, PA)项目由加拿大数字文本研究主席马塞洛·维塔利-罗萨蒂(Marcello Vitali-Rosati)负责协调,与包括意大利和法国学校在内的几家国际合作伙伴合作,旨在建立一个合作的关键数字版本和帕拉廷文集所有警句的多语言翻译。 希腊文学, 抄本, 数据库建设, 文本分析