

Jeffrey Tharsen / The University of Chicago
Clovis Gladstone / The University of Chicago
“Any text is constructed as a mosaic of quotations; any text is the absorption and transformation of another.”
—Julia Kristeva, Desire in Language[1]
Intertextuality has always been at the core of humanistic scholarly research, but it is only very recently that we have been able to leverage computational methods to help us in this endeavor. TextPAIR is a software package built specifically to detect “text reuses,” a particular manifestation of intertextuality where authors borrow sequences from other texts. Built upon a shingles of n-grams representation of texts,[2]the algorithm that drives TextPAIR relies on the relatively rare re-occurrence of any given n-gram to efficiently find common passages between texts.[3]While TextPAIR and other similar tools have been quite successful in uncovering borrowings between texts,[4]the growing size of digital corpora has led to a problem of scale, where the number of reuses found by the algorithm is such that it makes it difficult to gain an overall perspective of the phenomenon in these corpora.[5]Attempts at tackling this issue of scale have been mostly limited to user interface tweaks, such as faceted browsing — as seen in TextPAIR — and clustering methods meant to group together similar text reuses.[6]While these interface tweaks improved the experience somewhat, we have realized the need for rethinking our approach to the exploration of text reuses and developing a new exploratory interface specifically for the purpose of addressing the shortcomings of the standard search and retrieval functionality provided by TextPAIR. This newly developed package, called TextPAIR Viewer, leverages visualization techniques to provide a more scalable and interpretable perspective on the tens of thousands (even millions) of reuses detected by the TextPAIR algorithm.[7]
One specific goal of TextPAIR is to provide a mechanism that allows us to move beyond the “relational sociology” based on bibliographic methods (i.e., patterns of citations identified by scholars) described by Long and So[8](2013) and artfully employed by Nicholl-Johnson in his work on the Sanguozhi (《三国志》) and Shishuo xinyu(《世说新语》).[9]We sought to create an algorithmic method to produce intertextual analyses driven solely by the sources themselves, essentially a “relational literary analysis,” akin to the “intertextuality” of ideas, signs, and semiotics that Kristeva describes.[10]But with the scaling issue becoming more and more prominent as the size of digital collections — and with it, the ambition of scholars — grows, this original goal is no longer met. While TextPAIR has no trouble scaling up to over a hundred thousand texts,[11]it can be difficult for the user to apprehend the relationships between the potentially very high number of detected reuses. We have created the TextPAIR Viewer add-on precisely to overcome this difficulty and fulfill the original promise. By generating a visual representation of reuses, this add-on provides a distant-reading perspective on the “mosaic of quotations” that the TextPAIR algorithm by itself never could.
The current design of the TextPAIR Viewer provides a marked improvement in the way text alignments are presented to users. The key limitation of the standard TextPAIR interface lies in the pairwise relationship between each original passage and its reuse. While grouping results through faceted browsing certainly provides a more compact view of reuses, it still only highlights the relationship between one single text or author with a set of reuses. The main shortcoming of this grouping is that it does not help scholars understand how the authors (or works) that borrow from the same set of passages relate to one another. Indeed, the reality of intellectual influence is that each author or work may have multifaceted relationships with many other authors or works. It is thus important to consider reuses not so much as a strictly one-to-one relationship between the source and the borrower but rather as an intellectual practice that may, for instance, indicate the belonging of an author to a broader literary or cultural community. Therefore, as a distant reading tool, TextPAIR can only, at best, answer questions such as who reused an author/title the most or which author/title was most borrowed from, but fails to show whether there are any consistent patterns in the reuses by multiple authors or works. This is where the visualization techniques at the heart of the TextPAIR Viewer come into play. By leveraging the clustering nature of force-directed graphs, the TextPAIR Viewer places texts which tend to borrow from similar sources in specific areas of the visualization, thus highlighting distinct clusters of reuses (see the example below). These intellectual spheres are nearly impossible to identify with frequency tables as provided by faceted browsing.
One of our preliminary case studies in this endeavor was to examine patterns of citation, paraphrase and allusion in the entire corpus of “Twenty-four Chinese Histories” ( 二十四史 ), the official historical record of each dynasty in Chinese history, by algorithmically plotting — graph by graph, from history to history — changes in aligned passages as detected by the TextPAIR algorithm.[12]As TextPAIR allows for many-to-many relationships throughout any corpus regardless of source, one of the strengths of this approach is that we are not bound by the traditional view that assumes a chronological relationship in the composition of these works. For example, while we think it is certainly valuable to examine questions like how much of Sima Qian’s(司马迁,c.145–c.86 B.C.E.) original prose in the Shi ji(《史记》, the first history, chronologically speaking, dating to 90 B.C.E.) was adopted by Ban Gu(班固,32–92 C.E.) when the latter composed the Han shu (《汉书》, the second history in the chronology, dating to 111 C.E.), we can equally use TextPAIR to examine passages from the Shi ji that have identifiable parallels in any of the twenty-four histories, right through to the Qing shi gao (《清史稿》, the last history in the chronology, composed in 1928). And indeed, TextPAIR identified 204 examples of reuse from the Shi ji in the Qing shi gao, though all are quite short, under 20 characters in length; as one would expect, the detections of reuse with the Shi ji as the source are dominated by the Han shu (3,933 parallel passages)and Hou han shu (《后汉书》2,282).
In total, TextPAIR identified 322,916 cases of reuse throughout the “Twenty-four Histories.” The table below (Table 1) provides the results of the pairwise identifications, where the number in each cell represents the number of text alignments between the source document in the far left column and each of the target documents in the other columns.
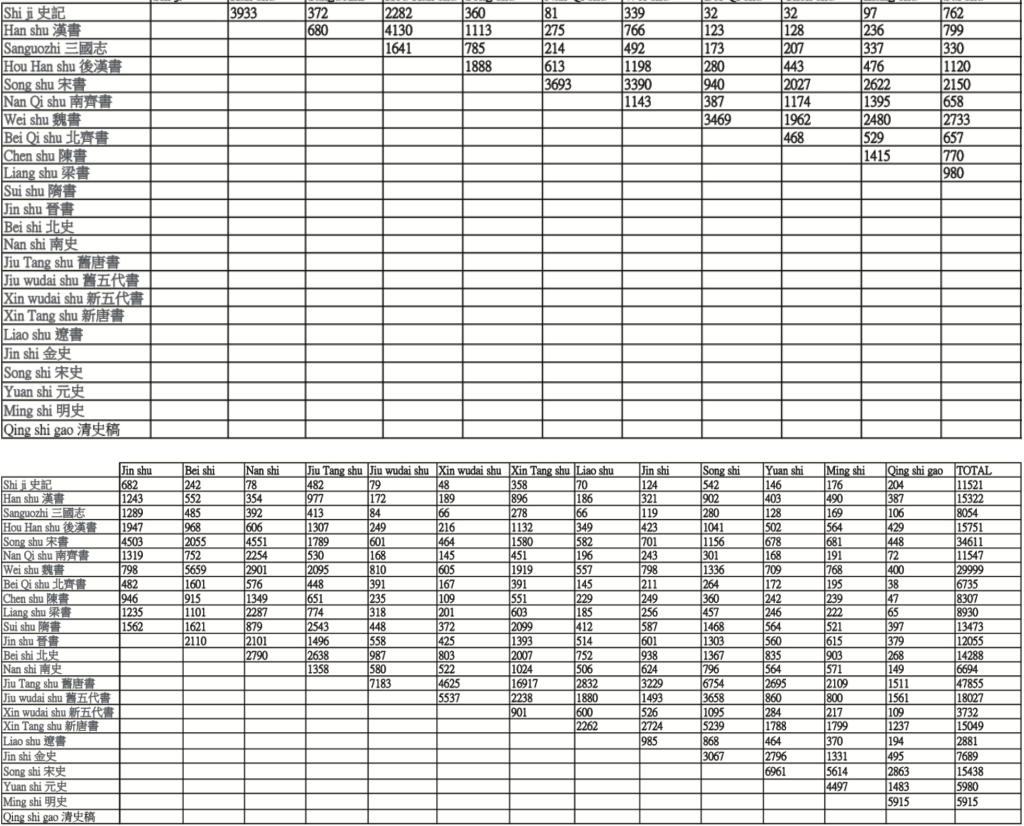
Table 1 Total pairwise reuses for each source and target detected by TextPAIR
Within these hundreds of thousands of alignments identified by TextPAIR, 82 comprised of at least 500 characters. One important aspect of TextPAIR, which drastically simplifies the work of comparing how the reuse of a particular passage differs from the original, is a feature called “Show differences” (Figures 2 and 3). Based on the Myers algorithm for the detection of the longest common subsequence between two strings of text,[13]it is implemented as a front-end plugin which runs on-demand and returns a character-by-character difference between passage pairs: deletions in the later passage are crossed-out in the source passage, and additions in the later passage are highlighted. This type of analysis can be very helpful in determining the strategies behind a particular reuse.

Figure 1 Shi ji vs. Han shu passage with “Show differences”

Figure 2 Jiu Tang shu(《旧唐书》) vs. Xin Tang shu(《新唐书》) passage with “Show differences”
While such a global table certainly helps in understanding the practice of reuse within the “Twenty-four Histories,” this table was compiled manually from results reported in the standard TextPAIR interface, and it also fails to uncover any pattern in the reuses (e.g., the centrality or peripheral location of various nodes). When these results are visualized, the interactive network looks like this (Figure 3).
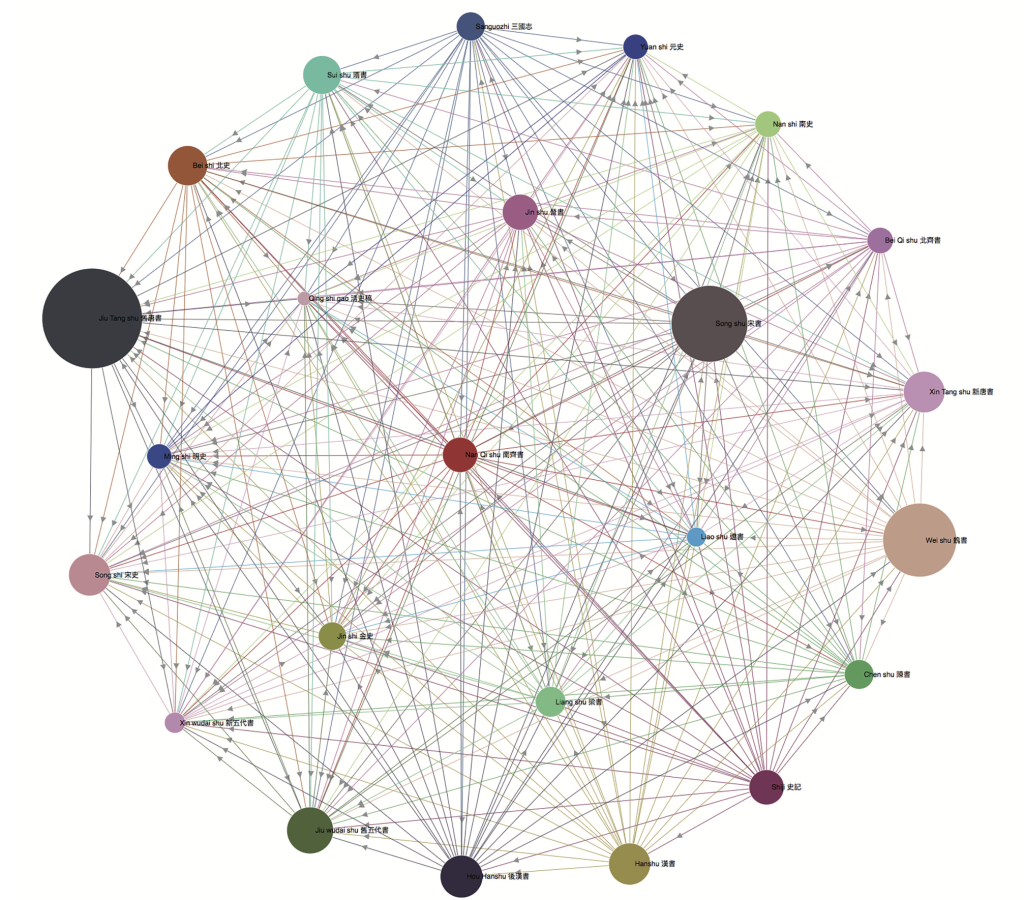
Figure 3 Force-directed network visualization of the “Twenty-four Histories”[14]

Figure 4 Force-directed network visualization of all alignments split by chapter within the “Twenty-four Histories”
As there are only twenty-four works in the corpus, all of which have cases of reuse, this visualization oversimplifies the complexity of the relationships between the works and also the numbers and variety of reused segments. At this point, in order to try to tease out the more fine-grained nuances, we decided to split each work into its constituent chapters and plot them against each other, including parallel passages that fall within different chapters of the same work. The result is a network of great complexity, with thousands of nodes representing the thousands of chapters (Figure 4).
Having attained proof of concept, we are now turning our efforts to transform the 1.0 version of the TextPAIR Viewer into a new 2.0 version with significant advantages. Primary among these will be redesigning the network engine to employ WebGL technology so that users can visualize complex networks (like the network above) in a browser on an average laptop or desktop. Our tests have shown that networks of tens of thousands of nodes tend to render very slowly and responsiveness is generally poor, making it difficult to efficiently explore these networks and the underlying alignments. In addition, we plan to make it possible to generate these networks on demand from within TextPAIR so that users can take any specific subset of the alignments (e.g., by selecting only specific texts or using keywords to narrow down the output) and produce a network of just those results. In other words, users will be able to leverage the Viewer tool to visually explore a predefined set of results and uncover potential patterns that would not be discernible in the standard TextPAIR interface.
We also have planned to update the visualization interface, such as adding a right-side interactive menu listing all the nodes that can be used to programmatically highlight all the communities within the network and the intersections between highlighted nodes. We would also like to include metrics like Laplacian eigenvectors and betweenness centrality for the nodes in the network so that users may easily discover which nodes have the greatest influence upon the overall network and serve as links between clusters of texts. One final change will be to move from two- to three-dimensional visualizations — yet another reason to move to a WebGL backend capable of rendering more complex scenes — in order to improve the visual clarity and facilitate the exploration of large-scale, complex networks.
We would like to reiterate that while the examples in this article have all been drawn from our corpus of the “Twenty-four Histories.” We have been producing networks for several large corpora of texts, in languages like French, English and Japanese, all with equal success. Our testing has shown that TextPAIR and the TextPAIR Viewer can be used for any language or Unicode script to identify and visualize text reuse throughout a corpus (or several corpora) of any size or complexity. We expect that these new tools will be of great assistance to scholars interested in intertextuality as well as those who wish to uncover the currents and changes in intellectual history over the longue durée.
(编辑:肖爽)
注释:
[1]Julia Kristeva, Desire in Language: A Semiotic Approach to Literature and Art, New York: Columbia University Press, 1980.
[2]In this representation, documents are converted to a series of overlapping word n-grams (blocks of n number of words) after a series of pre-processing steps which may involve lemmatization, stemming, filtering of non-distinctive words (e.g. stopwords) and so on. While the value of n is configurable, we have found that tri-grams offer a good trade-off between rarity and performance of the matching algorithm.
[3]TextPAIR is based heavily on two software packages: PAIR and PhiloLine. For a complete description of the matching algorithm, see Mark Olsen, Russell Horton, Glenn Roe, “Something Borrowed: Sequence Alignment and the Identification of Similar Passages in Large Text Collections,”Digital Studies/le Champ Numérique, vol. 2, no. 1, 2011, https://www.digitalstudies.org/article/id/7224/.
[4]See also Donald Sturgeon, “Unsupervised Identification of Text Reuse in Early Chinese Literature,”Digital Scholarship in the Humanities, vol. 33, no. 3, 2018, pp. 670-684; Paul Vierthaler, Mees Gelin, “A BLAST-based, Language-agnostic Text Reuse Algorithm with a MARKUS Implementation and Sequence Alignment Optimized for Large Chinese Corpora,” Journal of Cultural Analytics, 2019, DOI:10.31235/osf.io/7xpqe; John Wilkerson, David Smith, Nicholas Stramp, “Tracing the Flow of Policy Ideas in Legislatures: A Text Reuse Approach,”American Journal of Political Science, vol. 59, no. 4, 2015, pp. 943-956; David A. Smith et al., “Infectious Texts: Modeling Text Reuse in Nineteenth-Century Newspapers,” Proceedings of the Workshop on Big Humanities, Washington, DC: IEEE Computer Society Press, 2013.
[5]See our white paper for the NEH funded Commonplace Cultures project: hcommons.org/deposits/item/ hc:12365.
[6]See the Commonplace Cultures project: Charles Cooney, Clovis Gladstone, “Opening New Paths for Scholarship: Algorithms to Track Text Reuse in ECCO,” Digitizing Enlightenment: Digital Humanities and the Transformation of Eighteenth-Century Studies, eds. Simon Burrows, Glenn Roe, Oxford University Studies in the Enlightenment, Voltaire Foundation in association with Liverpool University Press, 2020.
[7]We would like to thank the Neubauer Collegium for its generous support for the development of the TPV as part of the “Visualization for Understanding and Exploration” project: vue.rcc.uchicago.edu.
[8]Richard J. So, Hoyt Long, “Network Analysis and the Sociology of Modernism,”Boundary 2, vol. 40, no. 2, 2013, pp. 147-182, DOI:10.1215/01903659-2151839.
[9]Evan Nicoll-Johnson, “Drawing Out the Essentials: Historiographic Annotation as a Textual Network,”Journal of Chinese Literature and Culture, vol. 5, no. 2, November 2018, pp. 214-249, DOI: https://doi. org/10.1215/23290048-7256976.
[10]This functionality is analogous to the Chinese Text Project tool outlined by Donald Sturgeon in his 2018 article, but with greater flexibility for analyzing any TEI-encoded corpus in any language and of any size.
[11]See, for example, our work on the “Practices and Legacies of the Enlightenment” project (artfl-project.uchicago.edu/legacy_eighteenth).
[12]Jeffrey Tharsen, Clovis Gladstone, “Using Philologic For Digital Textual and Intertextual Analyses of the Twenty-Four Chinese Histories(二十四史),”Journal of Chinese History, vol. 4, no. 2, 2020, DOI:10.1017/ jch.2020.27.
[13]TextPAIR uses the JavaScript implementation of the DiffMatchPatch library developed by Google, Inc.
[14]See https://users.rcc.uchicago.edu/~jcarlsen/TPV/TPV_histories/. Network visualizations in the TextPAIR Viewer 1.0 are created using the JavaScript D3 library’s force-directed network layout, with arrows pointing from the source node (a text that borrows from other texts) to the target node (a text that is borrowed from). The direction of the borrowing is inferred from the date of each text. The size of a node reflects the total number of text segments reused from that node; colors for the nodes are generated at random, edges are colored according to the source node.