

五十岚洋平 / 美国康涅狄格大学英语系
汪 蘅(译)/ 自由译者

五十岚洋平 / 美国康涅狄格大学英语系
汪 蘅(译)/ 自由译者
摘 要:作为两种文本阐释方法,细读与远读之间的关系成为有关数字人文能否适用于文学研究方面讨论的关键点。一般而言,细读被认为是充满个体性的、情感偏见的,而远读往往被归结为客观性的数据分析、并由此而被认为失去了人性的角度。事实上,从文学批评史的角度来看,统计分析在细读诞生之初即发挥了重要的作用。文章通过对新批评早期历史人物I.A.瑞恰慈之基本英语设计的梳理,挖掘细读和统计分析早期的、20世纪之初的互补性交汇关系,从历史的角度追溯细读究竟如何形成,以及它和与之连续的理论研究之间的相互影响,提出我们有必要更充分地恢复跨学科阅读研究领域中实施的统计分析,它们同文学研究和关于阐释及统计的持续讨论都高度相关。从而为当下的数字人文文学研究应用提供理论和历史上的合法性基础。
关键词: 细读 远读 基本英语 新批评 统计分析 瑞恰慈
效果如同摘下机器的盖子。
——威廉·燕卜荪《基本英语与华兹华斯》
当下数字人文引发的话语漩涡中,细读(close reading)作为文学研究的限定性阐释技巧,如何可能与文本分析的非细读(non-close)方法相关,已成为令人烦恼的问题。细读和非细读概念远非近来才初次相遇,而是在20世纪初用于教育的“词汇表”(word lists)领域内便已邂逅,记住这点或许有益。词汇表这一体裁中,所列单词通常以词频为基本标准,它在细读建立之初便形塑了后者。实际上,细读的创始人I.A.瑞恰慈(I.A.Richards)认为,名为基本英语(Basic English)的词汇表是教会学生更擅细读的最佳工具,该版本将英语压缩到仅剩850个单词——悭吝,但有用。的确,词频计数对细读的发展不负全责,甚至不是主要原因。但这种统计学分析在细读诞生之初发挥的重大作用与当下尤为相关,且未得到足够认可。细读发端时遇到的问题,和艾伦·刘(Alan Liu)在数字人文核心处识别出的“意义问题”相同:“定量阐释和人性角度有意义(humanly meaningful)的定性阐释”之间关系为何?[1]本文处理的问题和刘的一样,但路径相反,我们审视的不是目前“远距离”(distant)或“定量”分析中意义的状况,而是在瑞恰慈对“所有阅读的最初困难,即理解意义这个问题”细致的理论化中,“远距离”或“定量”分析如何起作用。[2]换言之,现在我们对人性阐释(human interpretation)和统计资料的关切重新涵盖了细读早期理论化伴随的那些关切。本文对细读或非细读的文本分析,既非辩护,也非批判,而是提出一段历史插曲加以考虑,希望能丰富我们对本学科中不同分析模式的理解;结论指出,阅读研究领域将是一个方向,对细读、统计分析及其关系探索的未来或将走向这里。
对于任何熟悉新批评理论化之前的细读概貌、C.K.奥格登(C.K.Ogden)和瑞恰慈共同发明并推广的古怪的(并古怪的迷人)“基本英语”项目的人,或熟悉基本英语对机器翻译系统直接影响的人来说,细读和统计分析早期的交汇不算新鲜。[3]然而在与数字人文相关的话语中,细读的到来与统计分析之间的关系迄今依然在睽睽众目中隐身。我推测有几种可能的原因。首先,有些宣布数字文本分析方法到来的重要阐述将细读去语境化了。例如弗朗科·莫雷蒂(Franco Moretti)对“远距离阅读”(distant reading,即远读)的阐述中,细读是“极为郑重地处理极少数极受重视的文本”;在N.凯瑟琳·海勒(N.Katherine Hayles)对数字人文的概述里,细读意味着“学习阅读复杂文本”,并代表了“传统人文”(Traditional Humanities)。[4]细读可能的确包含这些内涵,同时也要承认,这样的阐述从未声称要提供细读的详史。但令人遗憾,这些描述之笼统及其进步修辞(rhetoric of progress)妨碍人们认识到瑞恰慈1920年代后期研究工作中细读的诸种起源,以及他对基本英语密不可分的倡导,都浸淫于那个年代的非细读阅读方法,甚至在当时统计学的最新研究里。[5]另外,瑞恰慈认为细读和词频表彼此互补,是因为二者都可导向提高普遍读写能力(widespread literacy)这个社会目标。以下讨论首先对细读采取一种界定的、具体历史当中的理解,返回约翰·杰洛瑞(John Guillory)所称的“起始时刻”,目的是追溯细读究竟如何形成,以及它和与之连续的理论研究之间的相互影响。[6]
其次,数字人文话语往往关注数字技术,许多叙述反复讲到1940年代数字人文随着罗伯托·布萨(Robert Busa)主持的电脑生成托马斯·阿奎那(Thomas Aquinas)著作词汇索引而起源的故事。[7]不过,一旦从数字性的事实后退一步,便能看到更长的一段历史,涉及对统计方法的应用、19世纪对包括文学在内的语言加工品(linguistic artifacts)的“统计思维”,这些都远远早于数字人文或语料库语言学。[8]我赞同丽萨·吉特曼(Lisa Gitelman)确信的“肯定有其他……各种历史”,也就是那些考虑到“数字人文的前数字史”的叙述。[9]因此,以下讨论倾向使用“统计分析”,而非其他目前应用的术语。例如“定量”一词广泛流传,作为现今数字文本分析的代名词,其运用似乎类似于“统计”(statistical)这个词。然而我略偏爱“统计”,既然在文学研究中“定量”一词和“数字”(number)一样,已指向全然不同的一套对象和分析,有大量历史先例,且涉及韵律学。因此,“定量”的问题始于含糊不明,延伸至令人忧虑的事实:该术语用来赞颂当下研究中据称新颖的方法论性质时,会无意之中覆盖(overwrite)想象性话语与定量之间的漫长历史。[10]
“统计分析”也有别于莫雷蒂的“远距离阅读”和马修·约克斯(Matthew Jockers)的“宏观分析”(macroanalysis)。这两个术语都寻求通过专心挖掘大量文本将自己同细读分开:“可获取的数据的绝对数量就让传统的细读实践——作为穷尽或限定的证据收集方法——难以维系。”[11]莫雷蒂和约克斯强烈反对细读传统上对单个文本的关注,“统计分析”却能容纳史上收集并分析过的全范围对象,不只是分离的文本,还包括音素、字母和单词。另外这只是个偏好问题,但“统计分析”能让我们认识到对单个文本的前数字(predigital)统计解读和相应的数字分析之间的连续性,前者如威廉·燕卜荪基于频率标准的《〈奥赛罗〉里的诚实问题》,后者如史蒂芬·拉姆塞(Stephen Ramsay)对弗吉尼亚·伍尔夫《海浪》(The Waves)富于启发的分析。[12]
其实,“统计分析”不像“机器阅读”或“算法批评(algorithmic criticism),其定义不依赖数字或电子计算技术。后者是拉姆塞提出的名称,可能最接近“统计分析”,而拉姆塞也将其方法来源和一般意义上的数字人文一样追溯到布萨。[13]但历史记录显示,许多统计分析是手工制表和计算完成的,从词汇索引、意象群(image clusters)到词汇表体裁,它们在我以下阐述中将起到重要作用。[14]将数字性(digitality)理解或称颂为非细读的条件,并借此对前数字统计分析不屑一顾,这意味着赞成当下主义(presentism)最严苛的形式,忽视媒体研究对此类结论最为经典的告诫。[15]
最后,前进的同时,有必要更充分地恢复跨学科阅读研究领域中实施的统计分析,它们同文学研究和关于阐释及统计的持续讨论都高度相关。许多面向初等和中等教育的统计工具与研究结果已经并持续对大学层级的英语学科发挥显著影响。例如爱德华·李·桑代克(Edward Lee Thorndike)的《教师词表》(The Teacher’s Word Book,1921),这是语言艺术中地标性的现代资源,我们还会看到,它对瑞恰慈早期的细读理论也投下阴影。
桑代克的《教师词表》是当下文学研究采用的令人印象深刻的统计分析方法被遗忘的祖先。桑代克是心理学家威廉·詹姆斯(William James)和詹姆斯·麦肯·卡特尔(James McKeen Cattell)的学生,是教育心理学这门学科现代发展史上的关键人物,特别是由于他努力将统计学科学化并引入心理学。桑代克最著名的口头禅概括了他的信念,即“心理学需要全面采用统计学方法”,这句口头禅在他全部作品中以不同变体不断重复,于他的教科书《精神社会测量学导论》(An Introduction to the Theory of Mental and Social Measurements, 1904)中表达出来,并庄严地载入在他的悼词中——“万物存在于数量(quantity)中”。[16]《教师词表》稍为偏向其教育心理学著作主流,但与他的人类学习可量化的信念完全一致,阅读能力也不例外:“八年级结束时,普通儿童应该了解多少个英文词的含义?哪些词是这个阶段所有或几乎所有小学生都应该了解的?它们应该在哪些年级、哪些方面学习?我们无法正确回答,一个重要原因可能在于我们对小学生和毕业生将要或应该听到的谈话中、将要或应该读到的书籍、文章、信件等等当中单词的出现频率缺乏认识。”[17]
《教师词表》制作了一份万字列表,是总计约四百万现行单词(running words)里最频繁且广泛出现的单词。桑代克使用了四十一种资料,分为五个语料库:(1)“儿童读物”(例如《黑美人》[Black Beauty]和《小妇人》[Little Women]的章节,还有入门书、读本和几种科目的课本);(2)“标准文学”(摘自《巴特莱特常用语录》[Bartlett’s Quotations]的文学词汇索引和节选);(3)“常见事实与行业”(例如美国宪法,烹饪书,年鉴);(4)“报纸阅读”(从报纸计数);(5)“通信”(从信件计数)。尽管桑代克的计数收编了一些学者们已部分处理过的资料(例如《圣经》、弥尔顿、华兹华斯和丁尼生的词汇索引)和一些之前就有的频率列表(例如W.A.库克[W.A.Cook]和M.V.奥谢[M.V.O’Shea]对十三位美国信札作者私人通信的计数,发表于《儿童和拼写》[The Child and HisSpelling, 1914])里,但这一大规模任务还是花费了桑代克及助手们十年时间计数、制表。[18]
桑代克之前就有词汇表。最突出的是速记体系及其词汇表的深厚历史,可追溯至古代,而最早的英语的体系是文艺复兴时期提摩太·布莱特(Timothy Bright)的《符号:简略、快速、秘密的符号书写艺术》(Characterie: An Art of Short, Swift, and Secret Writing by Character, 1588)。[19]速写体系要么凭直觉,要么数出一种语言里最常见的发音、字母或词汇,因为这些高频字母、发音或词汇应配有最易写的符号。非细读或“远距离阅读”真实的历史很大程度上涉及速记(stenography)的历史,包含同样程度的手写(handwriting)和各种不同阅读模式。[20]受1898年F.W.凯丁(F.W.Kaeding)开创里程碑式德语词频计数的启发,同样出于速记需求,出于非速记用途的英语词汇表在20世纪初开始出现。例如伦纳德·P.艾尔斯(Leonard P. Ayres)很有影响的《拼写能力量表》(A Measuring Scale for Ability in Spelling, 1915)和之前提过的库克-奥谢通信计数,都寻求确定最常用的词汇,既然这些是学生最需要学会拼写的词汇。[21]但桑代克的《教师词表》是首个超越词频本身的词汇表,在计算单词频率时还会考虑它在“小学生或毕业生将要或应该会听到的谈话,……以及将要或应该会读到的书籍、文章、信件”中可能的分布。[22]为了完成这一目标,桑代克设计了一套“积分”标准。某一作品中的词语根据频率赋分:例如1—4次是1分;5—9次是2分;“儿童读物”中的多数资料以此类推。但整个语料库中积分值不同:“通信”资料中出现多达19次的单词也只得到2分,桑代克给它的权重低于“儿童读物”,因为后者是小读者更容易遇到的。[23]把来自41种资料的每个单词的积分加起来之后——桑代克记录了大约20,000个单词——在列表中给出了10,000个最“重要”的单词,让小学生了解。“in”是清单上的第一个词,总分211。“mean”“not hing”“order”“sea”“seem”都在100分左右,位于前500名单词之列。“gurgle”和“zest”靠近清单末尾,各自仅有3分。
《教师词表》的主要动机来自下述教学理念,即,学生在小学遇到的单词应更加精心控制,以备适合各自年级的水平。《教师词表》会让老师们在普通儿童读物中查阅特定词汇在统计上有多突出或罕见,例如雪莱的《致云雀》(Ode to a Skylark)(图1),然后决定如何向学生教授这些词——“有些(词)当时就应该解释,以达到故事或诗歌的目的,但之后就由它们自己了;有些词就应彻底教授并复习”。[24]
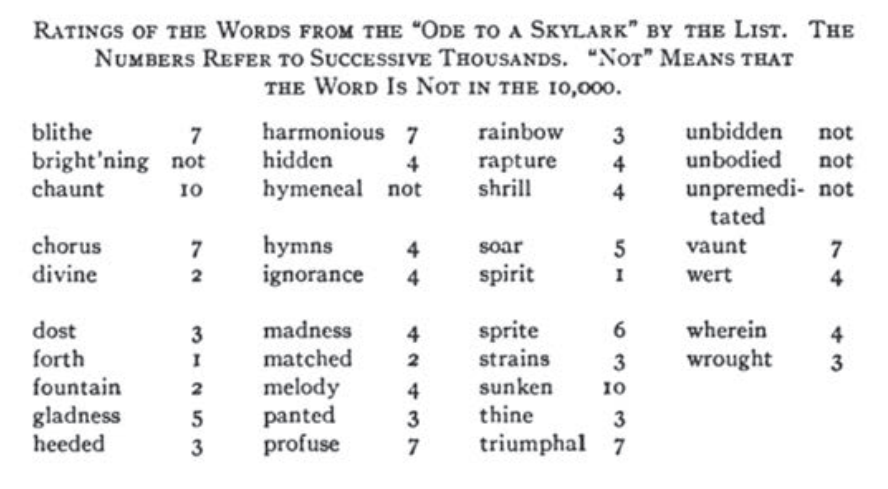
图1 摘自桑代克的《小学词汇知识》
根据本表对《致云雀》的词汇分级。数字指代连续的千个词。“NOT”表明该词不在这10,000个词当中。forth和spirit是高频词,在列表的第一组千字词里,divine在第二组千字词里,以此类推。
之后这份清单就成了标准,基础读本和其他初等课本据此系统性地选择并分级所使用的词汇。可以肯定,桑代克的词汇表里有严重的偏差,最显眼的是衍生词。与他所依赖的先前的计数对衍生词的处理不同,桑代克列表本身只有部分词目化(lemmatized);这就解释了雪莱诗中的“sunken”和“bright’ning”的低级别,尽管“sink”其实在前3,000词当中,“sunk”在前5,000词中,而“bright”在前2,000词中,“brighten”则在前5,000中。另外还有棘手的多义词问题:正如桑代克的批评者所指出的,以雪莱诗中的“strain”和这个词的其他含义为例,《教师词表》即无法分辨。不过,总体上《教师词表》满足了许多教育上的需求,影响巨大,卖出了2万多本。[25]1931年接着出了第二版,这次的词汇表有2万个词,基于对1千万单词的计数;继而又出了一版有3万单词的扩大版。为了回应关于含义的问题,桑代克和学生欧文·洛奇(Irving Lorge)出版了《英语词汇语义学计数》(1938),精选570个单词,根据《牛津英语词典》划分的单词指称(denotations)分解每个词的频率。[26]
桑代克在从事计数工作的同时,奥格登和瑞恰慈萌发了创建自己词汇表的想法。1918年,奥格登和瑞恰慈开始讨论并起草《意义的意义》(The Meaning of Meaning, 1923)。他们在做“定义”一章时,注意到世界上多数物体(语词的“指称对象”)都能根据它们与其他指称对象的关系来定义,这只需几种基本关系种类就能满足大多数基本定义:例如,相似性(“梨”像苹果);时空关系(“昨天”在今天之前);因果(“蒸汽”是烧水所致)。这些思考导致了奇怪的、更限于词典编纂意义上的实验。瑞恰慈回忆,在写这一章时,他和奥格登“突然盯着对方,说道:‘你知道这意味着用不到一千个词你就什么都能说。’如果一个单词能用不到十个词的描述性短语来定义,你就能用这十个描述词代替那个单词,然后去掉它”。[27]最终,这一“词语替代”算法将移除英语语言中大多数单词,仅留下一组功能词)可描述《意义之意义》中考虑的指称对象之间的基本关系种类),以及数百不可缺少的单词组成的工作词汇(working vocabulary)。“词语替代”是基本英语的萌芽——最初不幸称作“一目了然英语”(Panoptic English),之后十年,奥格登用他对杰里米·边沁(Jeremy Bentham)的语言理论和早期现代通用语言的研究继续开发这个词汇表。[28]
1929年,他出版了基础词汇表的初代版本。奥格登,一位博学家,为基本英语计划带来一套额外的哲学和理论装置。出于当前行文目的,其主要轮廓在下文会更具体地加以描述。

图2 基本英语词汇表
基本英语不同于构建的或“人造的”通用语(如世界语),它从现有的英语语言开始,通过“词语替换”得到850字的列表。该表相对较短,这很重要:基本英语号称自己和以前所有速记系统及通用语言一样,其体系能快速轻易地掌握,实际大约三十小时就能习得;[29]同样重要的是,基本英语的词汇表足够短,在单面纸上分栏印刷,依然清晰可见(图2)。基本英语通过使用100个“功能词”(operator)大量减少了词汇,功能词只包括十六个动词、两个助动词和二十个介词(另有基础词汇),但可以替代4,000多个动词。[30]例如,基本英语计划从其版本的英语语言中移除了enter和ascend,基本英语的写作者就代之以“go in”和“go up”。剩下的750个单词包括600个精心选出的“事物”(Things)(如“账户”[account]、“年度”[year])和150种“性质”(Qualities)(如“似有的”[private]、“尖锐的”[sharp])。富兰克林·罗斯福讲演的一段节选,“我注意到全国各地的信心,这太好了”(It has been wonderful for me to catch the note of confidence from all over the country)翻译为基本英语后呈现出冗长的风格——“这对我而言是很棒的体验,我意识到全国各地对未来的信心有越来越大的迹象”(It has been a great experience to me to be made conscious of the signs of an increasing belief in the future all over the country)。如果有人想写写sole——其意指“鳎鱼”,而不是指“脚底”的时候——奥格登提供了基本英语的描述即“口感细腻的小平鱼”(Small flat-fish with delicate taste)。[31]
基本英语有两个目标:“作为国际辅助语言……全球通用的第二语言,用于一般交流、商业和科学”;第二,“提供对普通英语的合理入门;既作为自然语言非英语人群的第一步,也作为语法介绍,鼓励任何英语运用达到熟练程度的人群清晰逻辑与表达”。[32]所以,一开始基本英语就有两个互不匹配且不相容的雄心。[33]从缩略语Basic一词中能看到(British American Scientific International Commercial,即英国、美国、科学、国际、商业),第一个目标是作为全球语言媒介,促进多种话语的信息沟通——科学的,政治的,等等——面向两次大战之间国际主义最明显的世界和平乌托邦理念。在这一点上,基本英语与其17、18世纪先驱没有区别,后者也在暴力冲突中为梦想驱使,希望通用语言导向普世之爱。[34]“基础”(basic)这个词表明了另一个目标,即作为相对简单的术语构成的词汇表,辅助母语和非母语人群学习英语。简单说,基本英语既渴望成为“孤岛词汇”(island vocabulary)——一种微型但全面的语言,同时也是一份以教育为目标的词汇表,就像桑代克的词汇表。
尽管看起来不同,基本英语和《教师词表》一样都是统计驱动。奥格登确实蔑视词汇表:他坚持说基本英语的“词汇不是由词语计数决定的最常用的那些”,并对《教师词表》激发的“词语计数大军”嗤之以鼻。[35]然而,奥格登在了解《按语与探询》(Notes and Queries)中的“词语计数”时注意到了《教师词表》,他研究了桑代克所得出的结论和发现;[36]他在开发本体系时写了大量有关基本英语的文章,这些都意在定位他的列表同桑代克及他人统计数据的关系。[37]毕竟桑代克已经提出的某些看法很类似基本英语作为国际语言的目标,声称他计数的前500个单词稍作改动便可作为“极有价值的基础词汇表,用于教授外国成年人阅读英文”。[38]而基本英语的第二个目标——“提供对普通英语的合理入门”——显示奥格登正在尝试一种类似桑代克的英语语言学习系统化。因此,对基本英语有研究的学者,例如丽塔·雷利(Rita Raley)和刘禾都认为基本英语是(用后者的话说)“对英语作为统计体系的构想”。[39]
刘禾论证说,奥格登将基本英语中反复出现的850个单词看作乔伊斯《芬灵根守灵夜》庞大词汇的对立面,后者每个词重现较不频繁(虽然这部小说那么冗长。如果小说短的话,那种情形就会是词汇多样性低的决定因素)。奥格登的直觉预见了克劳德·香农(Claude Shannon)和沃伦·韦弗(Warren Weaver)在《通讯的数学原理》(The Mathematical Theory of Communication, 1948)中对印刷出版物中英语(printed English)的随机分析,该书援引的恰是基本英语和乔伊斯的小说,作为信息冗余与熵的两个相反例证。[40]可以说,刘禾的看法和我一样,我们有必要按本意解读奥格登,他公开拒绝统计词汇表,声称基本英语非定量的、“以分析方法”选取的850个词优于以频次为基础的单词表——这是一种针对竞争对手的争论性的评论,有关统计词汇表的竞争激烈,且桑代克的观点居于统治地位。
奥格登坚持“语言学真正的统计任务与其说是确定被具体阶层的人实际使用的单词数量……不如说是如何最为经济地覆盖特定语义场(field of reference)”,他最初的合作者瑞恰慈更为客观,看出了《教师词表》与基本英语之间的密切关系。[41]瑞恰慈认为,基本英语的主要创新在于那100个高冗余“功能”词,这些基本英语的句法“老黄牛”(例如“放置”[put]、“给予”[give])被反复用来替代种类繁多的英文词汇——这些词语在桑代克的计数中频率也很高,事实上在前一千名内。瑞恰慈评论说,“无论我们是否满意,如同桑代克早期的词语计数……要确定哪些词在不同类型作品中出现最频繁,并将我们的列表建立在频次与范围(使用该词语的不同资料的数量)基础之上,或者如奥格登的研究,我们考虑过复杂得多的各种情况”,“关于这一百个功能词或结构词,对结果的影响没有太大区别”。[42]
显然,瑞恰慈沉浸于并熟悉这些词汇表及其呈现的数据。另外,1928年奥格登正在为基本英语词汇几个最初版本收尾,瑞恰慈也接近完成《实用批评》(Practical Criticism, 1929),两位作者见了面。会面后,瑞恰慈确信,大约十年前奥格登协助设计的词汇表对他正在撰写的关于细读的奠基性论述有重大影响:“他的简化英语(Simplified English)和我的《实用批评》交界处有许多东西要探讨。它们彼此有很大关联。他的东西是关于‘如何用最少的词语和结构说出任何内容?’例如,以‘get in’代替‘embark’,以‘get off’代替‘disembark’。”[43]
瑞恰慈正在寻找恰似基本英语的工具,他谋求更好的方式使用释义(paraphrase)来教授学生成为更好的读者。众所周知,瑞恰慈在他的“实用批评”实验中要求学生(及其他自愿参与者,包括诗人T.S.艾略特)对他发下来的诗歌做出评价性“解读”,而他事先已移除作者名、诗歌标题和明显的历史特征。[44]学生们一致面临的问题首先是不能抓住一首诗潜在的意义(sense)或“思想”,“本实验所带来的最为令人不安的、给人印象最深的情况,就是很大一部分中上水平的读者(当然,在若干实例中还有热心的读者)没能理解它……这种情况经常地、反复地发生。他们没能看出其作为一连串普通、易懂、与任何更为深远的诗意相分离的英语句子中那种散文的意味,没能看出其简单、明显的意思。他们总是在复述之中歪曲它。正像一个学童不能解释一篇凯撒的文章一样,他们也没能解释它”。[45]据瑞恰慈说,问题的来源是“诗歌语言简练”:这种紧凑让诗歌快速有效传达情感,但也“往往阻碍了散漫的话语信息,其机制是将观点散播开、分成不同的部分”。[46]瑞恰慈发现,学生做出评论与判断主要取决于诗歌或其形式激发的情感,但却基于对诗歌意义的不完全理解,或者更糟,他们全然忽略了领会诗歌意义这个任务。这一倾向正是《实用批评》将几种误读类型分类的原因。因此,尽管瑞恰慈在《实用批评》里没有概述完整、正式的细读方法,他暗示了推荐的阅读策略。在这种策略中,理解诗歌的意义在重要性和顺序上都是第一位的。瑞恰慈认为,只要读者不能领会诗歌的意义、阻碍整个阐释过程,“将观点散播开、分成不同的部分”就应该是感情——更别说惯性反应和不相干的个人联想——已然影响了读者反应之后首要特意的、规训性的活动。“所有令人尊敬的诗歌都要求细读,”瑞恰慈写道,这一过程总是首先要求“关注字面意义”。[47]
在完美世界里,释义会触发这样的关注,既然读者通过散文翻译诗歌时不得不考虑“简单的、明显的意思”,并逐渐揭露所有含糊之处,同时防止由人类阐释,也就是“读者的个人情境”导致的扭曲。[48]但释义就像教师们通常采用的那样,适得其反。瑞恰慈评论道,学生要么盲目求助于“挪动同义词”,导致“意义的所有存疑部分都未能阐明”,要么会“用散文体写一首主题上部分类似的诗”。[49]由于学生对拉丁语或法语的熟练程度日益捉襟见肘,无法应用其中任何一种作为媒介,将英文文学作品释义过来,那么解决办法只能是一种语言内翻译。简单讲,瑞恰慈确信释义是细读技巧中包含的最初、最具决定性的练习组成部分,但各处的老师们需要更加“合理的一般理解阐释技巧”。[50]
这就是基本英语出场之时机。瑞恰慈写完《实用批评》后又写了几本关于基本英语的书,包括少有人读的《实用批评》续集——《教学中的基本英语:东方与西方》(Basic in Teaching: East and West, 1935)。之后,他从剑桥、哈佛、美国的布林莫尔学院(Bryn Mawr)和中国台湾的新竹清华大学的教学体验中逐渐确定,通往《实用批评》“细读”技巧的第一步只能通过基本英语教给英国、美国和中国学生。[51]基本英语这样的词汇表可以防止学生靠“挪动同义词”解决释义:“其词汇极为有限”,瑞恰慈写道,“强迫你持续探索原文的含义。你不细致追究是无法将它置换成基本英语的”。[52]学生用基本英语,就不能仅仅逐字交换同义词,也更难忽视一首诗的措辞和模棱两可,而且用基本英语做出的单调啰嗦的诗歌基本版也让这一现象更突出。瑞恰慈在别处详细说明,“稍微练习后,难以写出基本英语版本这个问题就完全不再是难以找到基本英语的措辞,而变成难以确定原文究竟在说什么、可能或也许在说什么……那么这项练习就几乎成了纯粹的阐释练习”。[53]
注意,瑞恰慈首要之事是试图最小化飘忽不定的、主观和有感情的——简言之,人类的阐释倾向会瓦解对诗歌的分析。于是他取来一种统计方法,即基础词汇表,因为它是“有限媒介”:有限在于基本英语是有限词汇资源,有限也因为媒介会抑制(瑞恰慈如是希望)“反复无常的联想,情感回应的干扰”引诱读者离开这项任务,但这任务正是所有良好阐释和判断的源泉。[54]换句话说,瑞恰慈竭力要找到的阐释方法将会精准完成目前以数字方法实行的统计分析也在谋求的目标:“驱逐,或至少关键要延迟阐释开始时人的心理作用”,如艾伦·刘描述过的数字人文的“白板阐释”(tabula rasa interpretation)之梦。[55]当然,现在更可能用来与细读协作的词汇表可能是统计上来源于身为研究对象的作品或作者:有数字人文项目以信件的统计分析为辅助,做过艾米莉·狄金森(Emily Dickinson)诗歌的细读。[56]这方法与瑞恰慈或其学生燕卜荪不同,他俩都相信基本英语对整个英语语言的统计分析结果应该用一种确保读者在自身感情和联想面前相对不偏不倚的方式,来翻译和领会阐释诗歌。[57]
即使细读读者不去参考基本英语的单页词汇——相对较少的细读读者这么做过——并在第一步形成词汇受控的释义,基本英语还是提出了有关细读与非细读的重要理论问题:不在心里运行类似基本英语的简单高频词,如何实现细读,或与他人交流细读?某种程度上,文学作品不就是用基本英语词汇与非基本英语词汇生成的统计对象?其中非基本英语词汇可以通过“词语替换”程式翻译为基本英语。瑞恰慈和燕卜荪正是这样看待诗歌的。起码从历史角度,现在有可能承认,统计分析与细读联手运行,要么作为组件(component)促进细读,或作为细读的“插件”(plug-in);细读技术初始的理论化本身就被那个年代的“远距离阅读”形塑。[58]同样,人们反对“远距离阅读”是因为它明显对细读有敌意,但这些人也不得不承认统计学方法在阐释过程之初实现的这个重要功能。这两种方法被视为互补,“彼此有诸多关联”,如果我们用同样的或更深思熟虑的方式再次整合两者,或将有益。
统计分析与细读一度如此亲密之后,发生了什么?现在追溯一下它们如何逐渐分叉,一头进入阅读研究领域,另一头则是克林斯·布鲁克斯(Cleanth Brooks)对瑞恰慈细读方法的改变。先说第一个,《教师词汇表》和类似统计数据为一种研究体系的出现提供了条件,它始于1920年代教育心理学的“可读性”(readability)问题。可读性是仍然不断发展的研究领域,关注“写作风格导致的理解难易度问题”。[59]《教师词汇表》出版后,出现了一连串可读性数学公式——包括桑代克自己的测量方法——从1920年代直到1960年代的电脑单词计数。[60]乔治·R.克莱尔(George R. Klare)对这些可读性公式的历史做过述评,颇为有用。他提出,鲁道夫·弗莱什(Rudolf Flesch)1948年的“易读性(reading ease)公式也许最具影响。弗莱什认为《教师词汇表》混淆了词频与易读的概念;弗莱什仅仅在这此观点上同意奥格登,认为单词频率不像桑代克和做课本词汇分级的人设想的那么重要,更谈不上作为易读性的准绳。[61]正相反,弗莱什认为“简单程度……主要关乎句子结构和表达的具体性”。[62]因此,弗莱什加入了桑代克后来的可读性公式的瞩目潮流,将(桑代克或他人的)词频计数从等式中全部拿走:弗莱什公式最简单的版本是一个线性方程,其基础仅有两个变量:单词短,句子短。RE=206.835-.846wl-1.015sl,RE=Reading Ease(阅读易读性),范围为1至100,100代表非常容易,0则代表非常难。wl为每100个单词的音节数量。sl为每个句子的平均单词数量。[63]
例如本文第一段(“当下数字人文引发的话语漩涡中……”)的弗莱什“阅读易读性”约为206.835-(.846×154)-(1.015×29.167)=46.946,是大学水平的可读性。这里“易读性”完全取决于单词和句子短小,从这个角度,弗莱什批评基本英语就不奇怪了,因其句子冗长,曲折别扭。同时,许多诗歌例证说明,音节少的单词串成短句子,可能造成令人困惑的结果。如果说《教师词汇表》混淆了词频与易读性,那弗莱什的“平常用语”(plain talk)理念假设简短即可读,也是错误的。[64]不过弗莱什公式仍是阅读研究范围之外应用最广的可读性方程,如今不同版本的公式继续出现于微软文档“拼写与语法”功能中的“可读性统计”里。
同时,布鲁克斯对瑞恰慈作品的研究也有充分记载,可以说,他了解瑞恰慈的基本英语工作以及关于词汇表的争议。[65]不管怎么说,布鲁克斯自己了解词汇表体裁:他的首部著作是一本纯粹语文学的研究,名为《阿拉巴马—佐治亚方言与大不列颠各地方言的关系》(The Relation of the Alabama-Georgia Dialect to the Provincial Dialects of Great Britain, 1935),大量吸收了一份1909年的阿拉巴马东部方言俗语表达法的词汇表。[66]另外,布鲁克斯及合作者罗伯特·潘·沃伦(Robert Penn Warren)致力于《现代修辞》(Modern Rhetoric, 1949)时,参考了弗莱什流行的可读性手册《平常用语的艺术》(The Art of Plain Talk, 1946),最终借用了弗莱什的释义练习——即,将错综复杂的段落重写为“平常”风格——用于其作文教材(composition textbook)。[67]一旦如此回顾布鲁克斯的解读,不由令人捉摸:在布鲁克斯关于阐释的理论著作及更广义上的新批评中,词汇表和“对语的统计学构想”去哪儿了?这些主题的缺失,显然无过于布鲁克斯通过《精致的瓮》(The Well Wrought Urn)谈及的各种令诗歌“艰涩”的方式而完全没提到词汇——而这一范畴受制于桑代克之后持续的统计分析,是瑞恰慈的基本英语释义练习的核心,并且在布鲁克斯的解读和即时历史语境中无所不在。[68]
在瑞恰慈那里,统计分析/细读联合的命运何以如此突出,只需简单看一下布鲁克斯《精致的瓮》里对“释义之异端”(heresy of paraphrase)的著名看法,便可阐明。当然,“释义之异端”成了新批评阐释的标志性信条,指的是错误地认为“诗歌构成某种‘陈述’”,即认为一首诗能缩减为一段散文信息。[69]但上述叙述揭示,布鲁克斯对释义自相矛盾地举棋不定。一种看法是“释义之异端”说明的,由科学导致的认识论焦虑迫使布鲁克斯坚持诗歌的意义不在于任何可以命题方式提取的“内容”——就像科学事实中那样——而在于诗歌吊诡的结构中。这个看法认为诗歌比科学具备更大的“真理”,无法将其简化为可验证的陈述,只能通过对诗歌结构或形式的细读来对待。[70]在这点上,布鲁克斯的“释义之异端”原则严重损坏了瑞恰慈最初对细读的概述——对诗中张力的注意替代了释义作为细读的核心过程。
但是布鲁克斯也以另一方式理解释义,它植根于教学现实。他并不反感实际的释义练习,这和瑞恰慈一样。我们知道,他在《现代修辞》中依赖释义练习,但也理解它在阅读诗歌时不可或缺:他承认释义可以是“阅读诗歌必要的预备步骤”,甚至承认,他在《精致的瓮》各章中的阐释不过是散文体的勾画,甚或是基本英语式样的。[71]从这个角度,释义很难说是异端。不过,布鲁克斯只是在重复我们所见的瑞恰慈告诫过的事,即学生被要求释义一首诗,很容易“用散文体写一首主题上部分类似的诗”,从而忽视诗歌的其他方面(例如音调);回想起来,这对瑞恰慈来说,是用基本英语释义的基本原理。
所以布鲁克斯令人难忘的名言“释义之异端”,最终模糊了他对释义颇为矛盾的立场,并导致释义总体上被摒弃。这又带来严重后果:初等和中等水平者的阅读、词汇问题、桑代克及其传人的研究、可读性、统计分析与释义的联结,这些全都从新批评阐释中被切除。只要我们将这一发展历程和瑞恰慈自己的信念相对比,就能确定这一点;他坚信“细读”问题必须贯彻至教育体系较低等级。“我决定放弃作为学科的文学,进入初等教育”,瑞恰慈写道。他后来将会关注读写能力,甚至为此目的而编写了儿童课本。[72]
新批评和阅读研究的关注点最为重叠时,却未能囊括阅读研究,目前我们应如何避免重蹈覆辙?数字功能可见性(digital affordances)容许对文学作品和文学史有启发、有价值的不同形式的统计分析,但这一阐述指出,还有机会让文学研究人员再次从阅读研究中学习并为其做出贡献,该领域一直以来都在研究阐释并应用统计学。英语学教授喜欢抱怨学生对于大学水平的读写有多么缺乏准备。那么我们承认,文学研究涉及的这些知识与能力的教导并非始于大学第一天。如果我们投入更多时间研究初等、中等和大学层级的读写能力、阅读和写作,不仅关照最后那一级,而是结合所有三个层级,并最终针对基本英语的一个最初目标——“鼓励清晰逻辑与表达”,那会如何?
Statistical Analysis at the Birth of Close Reading
Yohei Igarashi
Abstract: The balance between close reading and distant reading, as two interpretive methods, has been a determinant factor when it comes to be about whether digital humanities methods work in studies of literary works. Generally speaking, close reading is taken as individually subjective and therefore potentially with emotional prejudices, while distant reading is performed with objective data analysis and thus probably without humanly meaningful perspectives. What runs counter-intuitively for many people, statistical analysis played a very meaningful role in the beginning of the establishment of close reading as an analytical method. This essay reveals a mutually complementary relationship between close reading and statistical analysis, as it existed in the beginning of the twentieth century, through a historical description of I. A.Richards and his Basic English plan. It proposes that we should restore the statistical analysis as once implemented in cross-disciplinary reading research, which relates significantly to literary studies and the continuing discussion regarding interpretation and statistics. A kind of theoretical and historical legitimacy is therefore provided for applying digital humanities into studies of literature for the present.
Keywords: Close Reading; Distant Reading; Basic English; New Criticism; Statistical Analysis; I. A. Richards
(编辑:姜文涛)
a*原文信息: Yohei Igarashi,“Statistical Analysis at the Birth of Close Reading,” New Literary History, vol.46, no. 3, Summer 2015, pp. 485-504, DOI: 10.1353/nih.2015.0023。 Translated and published in Chinese with the author’s permission.
注释:
[1]Alan Liu,“The Meaning of the Digital Humanities,” PMLA, vol. 128, no. 2, 2013, p. 415.Liu详尽探讨了以下作品:Ryan Heuser and Long Le-Khac,“A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method,” Stanford literary Lab Pamphlet, vol.4,2012。这是Heuser和Le-Khac对其“阐释的假设检验模式”所做的可贵反思(p.49)。
[2]I.A. Richards, Practical Criticism: a Study of Literary Judgment, New York: Harcourt, Brace & Co.,1929,p.174.
[3]Rita Raley令人信服地表明,机器翻译从19世纪中期来临直到当下,是如何采用基本英语的功能性、表演性和普适性逻辑的。见Raley,“Machine Translation and Global English,” The Yale Journal of Criticism,vol. 16,no.2,2003,pp.294-295。之后会很清楚,我的叙述也和下文一致:David Simpson,“Prospects of Global English: Back to BASIC?” The Yale Journal of Criticism, vol. 11,no.1,1998,pp.301-307,文中强烈批评了文学研究领域人员对基本英语的相对忽略。非常感谢Christine Mitchell警醒我,基本英语与机器翻译之间存在联系,也感谢她在对本文较早版本的回复中其他有益的想法。
[4]Franco Moretti,“Conjectures on World Literature,” New Left Review, 2000, p.57; N. Katherine Hayles,How We Think: Digital Media and Contemporary Technogenesis, Chicago: University of Chicago Press,2012, p.11,p.29.
[5]例如,C.K.奥格登很可能与瑞恰慈一样,也了解他们的同时代人、剑桥统计学家G.Udny Yule的研究,包括:G. Udny Yule et al.,“The Function of Statistical Method in Scientific Investigation,” Industrial Fatigue Research Board (Report no. 28), 1924;M.G.Kendall,“The Statistical Study of Literary Vocabulary,” Nature, vol.153,1944,pp.570-571。
[6]John Guillory,“Close Reading: Prologue and Epilogue,” ADE Bulletin,vol.149,2010,p.8.本文也受到Guillory关于细读的其他研究的启发,特别是关于细读起源的一章,2007年在纽约大学举办的研讨会上传阅,另外还有一次关于瑞恰慈和神经心理学的讲演,后者最近发表于2015年MLA大会。
[7]这个起源故事一再被重复,例如Hayles, How We Think, p. 23和Matthew L. Rockers, Macroanalysis: Digital Methods and Literary History, Urbana: University of Illinois Press,2013,p.3。
[8]关于“统计思维”,我提到Theodore M. Porter, The Rise of Statistical Thinking, 1820-1900, Princeton, NJ: Princeton University Press, 1986,它说明了前学科统计思维的历史,当时社会科学与生物科学都在繁荣发展。以下我会提到速记相关内容,20世纪前统计思维与语言之间有许多有趣的交叉。关于语料库语言学的兴起,参见:Tony McEnery and Andrew Hardie,“The History of Corpus Linguistics,” The Oxford History of Linguistics, ed. Keith Allan, Oxford: Oxford University Press, 2013,p.728。
[9]Lisa Gitelman, Paper Knowledge: Toward a Media History of Documents, Durham, NC: Duke University Press, 2014,p.56.
[10]关于“定量”,OED解释为“关于或基于元音长度”。另见Prosody:(韵律等)基于音节长度而非重音所在。有大量方法和主题都落脚于“定量”和文学交叉处,例如与韵律相关的形式主义方法、数字学、政治经济同文学话语的关系、华莱士·史蒂文斯的“双重生涯”,都表明定量或量化并不是现在它典型描述的非细读阅读的理想名称。
[11]Jockers, Macroanalysis,p.9.
[12]关于使用的文本数量,我的阐述可能与Stephen Best和Sharon Marcus的“表面阅读”(surface reading)概念相似,如果他们所提出的表面阅读也能在单个或多个文本上实施。Marcus和Best摒弃“症候式阅读”时,提出了“表面阅读”这个庞大范畴,包括各种现存或新出现的学术方法及实践(书籍史、细读、认知方法、叙事学、话语分析、数字方法),都对症候学意识形态批判不感兴趣。统计分析可以是一种表面阅读,但它们大抵也能轻易满足症候式阅读要求;文学对统计学的应用没有什么本质上“表面”之处。见Stephen Best and Sharon Marcus, “Surface Reading: An Introduction,” Representations, vol. 108, no.1,2009,pp.1-21。
[13]Stephen Ramsay, Reading Machines: Toward an Algorithmic Criticism, Urbana: University of Illinois Press,2011,p.1.
[14]也值得记住的是,尽管莫雷蒂的研究说明了数字人文的文本分析方法,但他在《文学的屠宰场》里叙述的重要的“远距离阅读”实验是由人工阅读与制表完成的。参见:Moretti, “The Slaughterhouse of Literature,” MLQ,vol.61,no.1,2000,p.220。
[15]例如雷蒙·威廉斯就解释过长久以来技术是如何“在心里已有特定目标和实践时被寻找并开发的”,见Raymond Williams: Television: Technology and Cultural Form, London: Routledge, 2003,p.7。David Thorburn和Henry Jenkins讨论了较早的做法如何在媒体转换过程及之后坚持下来,见Thorburn and Jenkins,“Introduction: Toward an Aesthetics of Transition,” in Rethinking Media Change: The Aesthetics of Transition, Cambridge, MA:MIT Press,2003,pp.1-16。另见Alan Liu,“The Meaning of the Digital Humanities,” pp.416-418,文章倡导一种对科技与媒体有更长远考虑的“科学技术研究”方法。
[16]《心理学家E.L.桑代克博士去世》,《纽约时报》(The New York Times),1949年8月10日。
[17]Edward L. Thorndike,“Word Knowledge in the Elementary School,” Teachers College Record, vol. 22,no.4,1921,p.334.
[18]Thorndike,“Word Knowledge,” pp. 334-341.尽管不清楚究竟是谁协助桑代克完成这本怪书的首版,但桑代克和洛奇后期的语义计数依靠的是WPA(公共事业振兴局)工人。参见Works Progress Administration, Index of Research Projects, vol. 1, Washington: U.S. Government Printing Office, 1938-1939, p.67。不管是否涉及大萧条时期工人、“信息女工”、亚马逊机械特克或其他人,这些案头工作都有极大量的计数、制表、打字、复制、语料库建立、OCR修正等,全都提出了关于不公平劳动行为的问题。关于20世纪初“信息女工”,参见:Natalia Cecire,“Ways of Not Reading Gertrude Stein,” ELH, vol. 82, no. 1, 2015, pp. 281-312。
[19]Charles C. Fries and A. Aileen Traver, English Word Lists: A Study of Their Adaptability for Instruction, Ann Arbor, MI: The George Wahr Publishing Co., 1950,p.2.
[20]除了速记,建立词语索引也需要手写;Lane Cooper,“The Making and the Use of a Verbal Concordance,”The Sewanee Review, vol. 21, no. 2, 1919, pp .191-195,描述了作者如何编纂华兹华斯词语索引。Cecire的“Ways of Not Reading Gertrude Stein”通过一系列出色解读和关联表明,“远距离阅读”的真实历史也涉及女性化劳作如打字,还有围绕后来称为“斯泰因式”风格的争议。 Benjamin Morgan在其著作The Outward Mind: Materialism, Science, and Aesthetics in Nineteenth-Century Britain(与作者的电邮通讯)里,还原了 Thomas Corwin Mendenhall、L. A. Sherman和Robert Moritz等人作品中重要的维多利亚时代的“文学度量”(literametrics),它对比了不同作者和体裁词语和句子的长度。
[21]Fries and Traver, English Word lists,pp.4-18.
[22]Fries and Traver, English Word Lists, p.21.
[23]Thorndike,“Word Knowledge,”p.361,p.354.桑代克对他设计的计数不同种类读物中单词分布的积分系统态度含糊,要读者“任意接受这些积分”(“Word Knowledge,”p.335)。
[24]Thorndike,“Word Knowledge,”p.355.
[25]Geraldine Jonçich, The Sane Positivist: A Biography of Edward L. Thorndike, Middletown, CT: Wesleyan University Press, 1968,p.393.
[26]Lorge,“The English Semantic Count,” Teachers College Record, vol. 39, no. l,1937,pp.65-77;Lorge,The Semantic Count of the 570 Commonest English Words, New York: Institute of Psychological Research, Teachers College, Columbia University, 1949,pp.v-ix.
[27]Richards and Reuben Brower,“Beginnings and Transitions,” in I. A. Richards: Essays in His Honor, eds. Brower, Helen Vendler, and John Hollander, New York: Oxford University Press, 1973,p.34.
[28]C. K. Ogden,“The Universal Language,” Psyche, vol. 9, no.3,1929,p.1.
[29]Ogden, The System of Basic English, New York: Harcourt, Brace and Co.,1934,p.4.
[30]Ogden, The System of Basic English, p.4.
[31]Ogden, The System of Basic English, p. 151; Ogden,“Progress of Basic,” Psyche, vol. 10,no.2,1929,p.36.一方面,基本英语处理行话、官话、拐弯抹角的话和诗歌特别在行。另一方面,其有限词汇和冗长风格又很不实用,于是奥格登和瑞恰慈以强迫性方式处理,很有意思,他们用基本英语大量产出节选或整个文本(《圣经》《卡尔与安娜》《鲁滨逊漂流记》)的翻译,以及词汇表和其他元话语指南;很多时候奥格登和瑞恰慈在自己的书里推广基本英语,悄悄地从某个点开始用基本英语写作,之后要读者承认从英语向基本英语的转化有多不明显,也就是说基本英语实际上有多么顺畅好读(例如Richards, Basic English and Its Uses, London: Kegan Paul, Trench, Trubner & Co., 1943,p.20)。
[32]Ogden, The System of Basic English, p.4.
[33]后来奥格登与瑞恰慈因这两个目标产生分歧,甚至疏远。奥格登幻想全球应用基本英语,他经常提到“去语言交流障碍”(debabelization)。瑞恰慈和燕卜荪等盟友则认为基本英语最大用途在于促进对文本的理解。最终,瑞恰慈正式斩断同奥格登的基本英语运动的联系,但他从未停止捍卫基本英语作为细读工具的用途。参见:Richards, Selected Letters of I. A. Richards, ed. John Constable, Oxford: Clarendon, 1990,pp. 117-120。
[34]Murray Cohen, Sensible Words: Linguistic Practice in England, 1640-1785, Baltimore: Johns Hopkins University Press, 1977, p. 19; Kevis Goodman, Georgic Modernity and British Romanticism: Poetry and the Mediation of History, Cambridge: Cambridge University Press, 2004, pp. 24-26.
[35]Ogden, The System of Basic English, p. 30.
[36]Ogden,“Editorial,” Psyche, vol. 9, no. 5, 1929, pp. 5-6.
[37]Ogden,“Progress of Basic,” pp. 22-26; Ogden, The System of Basic English, pp.22-32.
[38]Thorndike,“Word Knowledge,” p. 364. 尽管早期说辞含糊,后来桑代克的单词统计表脱离了通用语项目。参见: T. Sawamura: Interim Report on Vocabulary Selection for the Teaching of English as a Foreign Language, London: P. S. King&Son, 1936, p. 1。
[39]Lydia H. Liu, The Freudian Robot: Digital Media and the Future of the Unconscious, Chicago: University of Chicago Press, 2011, p. 91; Raley,“Machine Translation and Global English.”
[40]Liu, The Freudian Robot, p. 99.
[41]Ogden,“Editorial,” p. 9.
[42]Richards, Basic English and Its Uses, p. 62.
[43]Richards, Selected Letters, p. 46.
[44]John Paul Russo, I. A. Richards: His Life and Work, London: Routledge, 1989, pp. 294-316. 人们想知道,既然瑞恰慈了解桑代克的心理学和教育心理学著述,他的实践批评实验是否受到桑代克的阅读理解实验及其对阅读错误分级的影响,有关内容参见: Richard L. Venezky,“The History of Reading Research,” in Handbook of Reading Research, eds. P. David Pearson et al., New York: Longman, 1984, pp. 16-17。
[45]Richards, Practical Criticism, p. 12.
[46]Richards, Practical Criticism, p. 204.
[47]Richards, Practical Criticism, p. 195.
[48]Richards, Practical Criticism, p. 227.
[49]Richards, Basic in Teaching: East and West, London: Kegan Paul, Trench, Trubner& Co., 1935, pp. 56-57.
[50]Richards, Practical Criticism, p. 294.
[51]Richards, Basic in Teaching, p. 49; Russo, I. A. Richards, p. 298.
[52]Richards, Basic English and Its Uses, pp. 107-109.
[53]Richards, Basic in Teaching, p. 84.
[54]Richards, Basic English and Its Uses, p. 94; Richards, Practical Criticism, p. 13.
[55]Alan Liu,“The Meaning of the Digital Humanities,” p. 414. 关于对这个梦的抒情拆解及“表面阅读”的若干方面,见Ellen Rooney,“Live Free or Describe: The Reading Effect and the Persistence of Form,” Differences, vol. 21, no. 3, 2010, pp. 112-139。
[56]Matthew Kirschenbaum,“The Remaking of Reading: Data Mining and the Digital Humanities,” http://www.csee.umbc.edu/~hillol/NGDM07/abstracts/talks/MKirschen- baum.pdf.
[57]燕卜荪举了一个很好的例子说明基本英语如何用于细读,见“Basic English and Wordsworth (A Radio Talk),” The Kenyon Review, vol. 2, no. 4, 1940, pp. 449-457.
[58]我借用了Alan Liu对“插件”令人印象深刻的用法,参见:“The Meaning of the Digital Humanities,” p. 415。
[59]George R. Klare,“Readability,” in Handbook of Reading Research, ed. Pearson et al., p. 681.
[60]Jeanne S. Chall,“The Beginning Years,” in Readability: Its Past, Present, and Future, ed. Beverley L.
Zakaluk and S. Jay Samuels, Newark: International Reading Association, 1988, pp. 2-7; Venezky,“The History of Reading Research,” p. 24.
[61]Rudolf Flesch, The Art of Plain Talk, New York: Harper & Brothers, 1946, p. 173.
[62]Flesch,“How Basic is Basic English?,” Harper’s Magazine, 1944, p. 341.
[63]George R. Klare, The Measurement of Readability, Ames: Iowa State University Press, 1963, pp. 58-59. 弗莱什自己还提供了许多其他测量方法(The Art of Plain Talk, pp. 58-65),或以弗莱什原始测量方法为基础,例如弗莱什与金凯德(Flesch and Kincaid)方法(Klare,“Readability,” p. 693)。
[64]Guillory,“The Memo and Modernity,” Critical Inquiry, vol. 31, no. 1, 2004, pp. 123-132. 重点见于 p. 126及p. 49。
[65]Cleanth Brooks,“I. A. Richards and Practical Criticism,” in The Critics Who Made Us: Essays from Sewanee Review, ed. George Core, Columbia: University of Missouri Press, 1993, p. 46.
[66]Brooks, The Relation of the Alabama-Georgia Dialect to the Provincial Dialects of Great Britain, Baton Rouge: Louisiana State University Press, 1935, p. 4.
[67]Cleanth Brooks, Robert Penn Warren, Cleanth Brooks and Robert Penn Warren: A Literary Correspondence, ed. James A. Grimshaw, Columbia: University of Missouri Press, 1998, pp. 134-137.
[68]Brooks, The Well Wrought Urn: Studies in the Structure of Poetry, New York: Harcourt, 1947, p. 76.
[69]Brooks, The Well Wrought Um, p. 196.
[70]Guillory, Cultural Capital: The Problem of Literary Canon Formation, Chicago: University of Chicago Press, 1993, pp. 159-160.
[71]Brooks and Warren, Understanding Poetry, New York: Henry Holt and Co., 1938, p. xi; Brooks, The Well Wrought Um, p. 206.
[72]Richards and Brower, “Beginnings and Transitions,” p. 29.