

作者:李友仁;转自:公众号 DH数字人文
文本分析

李友仁 / 荷兰莱顿大学数字人文中心、美国威廉·玛丽学院
汪 蘅(译) / 北京大学英语系
————————————————–
摘要: 虽然野史和其他准历史文本在明清时期很受欢迎,但它们缺乏文学学者关注。小说的巨大数量和当时出版的野史的数量使得对它们之间的关系进行研究,并不是一件容易的事。用准历史文本数字转录本的词汇频率列表进行统计学和线性代数分析,定位不同文体文本间相互关系,使用计量文体学分析来可视化文献间关系,可突出虚构文本和历史文本间的相似与不同;通过量化分析数字文本,可判断文本内部证据是否提示了野史本身构成有内聚力的范畴,并将它们同其他历史及准历史叙述的关系视觉化。定量聚类分析能清楚区分野史、小说和戏剧,研究词汇特征对这些风格关系的贡献可知,正史、野史和小说沿连续的梯度变化曲线落下,通过特定关键术语变量产生几个维度,由此确定曲线,这些术语同明清时期文言与白话的对比密切相关。
关键词: 野史 准历史 小说 计量文体学 定量聚类分析
————————————————–
明末清初(1550-1700)的中国,非官方的(unofficial)历史叙述极为流行。当时,形形色色的历史和准历史文体(semi-historical genres)繁荣兴旺,包括非官方的历史的“野史”(wild histories)、关于历史事件的小说(novels)、关于历史事件的戏剧(dramas)。这些构成了一组相关但又有不同的历史写作风格的文本,我统一称之为准历史(quasi-histories)。这是个涵盖性术语,所描述的文本体系包含某些历史内容,但存在于一系列广泛的文体中,各有不同的风格特征和文化意义[1]。虽然野史和其他准历史文本在明清时期很受欢迎,但由于许多文本被认为笔法拙劣,文学价值微不足道,缺乏文学学者关注,导致人们对其知之甚少。考虑到用文本细读方法分析这些文本所需的时间与精力,这种不关注也并不意外。尽管如此,这些文本对于理解明清文学和文化生产很重要。野史与准历史小说和戏剧一样,在信息传播中起到重要作用,影响了同时代读者对近期事件的理解[2]。这种文体(genre)相当流行,尤其在公务之余的文人写作(literati writing)中,这也进一步证明对其额外详加研究是有意义的。通过探索性地尝试量化这些作品与更经典的文本之间的文本关系,我就可以将这些作品纳入我的学术研究、并略去对质量做规范性(normative)评价。更重要的是,这让我可以开发准历史作品的文体分类法(a stylistic taxonomy),并以此提供基础去了解这些文本如何被阅读和分类(categorized)。
与此处探讨的准历史文本有关的文体是个复杂的概念。文体一般被理解为由一套颇为一致的风格惯例(stylistic conventions)形成的文本归类。这些惯例适用于定量分析。然而文体也有社会维度,詹明信指出,文体是读者和文本间由社会建构的“契约”,定义了预期(expectations)[3]。某些文体中,预期由官方目录学家由上而下推行。其他情况下,例如戏剧里,预期则自然发展。有时无法消除风格中的社会含义(disambiguate the social from the stylistic),许多内容相似[4]但文体不同的文本在不同文化阶层流传。野史及其他准历史文本存在的空间里,文体的文化建构有时与其风格建构相冲突。
这些历史书写中,有些作品的内容、风格和文体的性质激起了相当多争议,而野史是受争议最多的。野史虽然从未成为官方书目类别,但有许多是模仿官方历史文献风格的传统历史编纂作品[5],其他作品的风格和内容都无法同小说区分开。这双重性质引发了当时和现代评论家的许多警告:野史的价值,在于它们有助于理解被官方文献忽略的事件,但其遭到诟病的往往还是虚构的本质令其从根本上不可信赖[6]。
明清时期许多野史被官方目录学家归类为“小说”(petty talk,细小琐碎的谈论)。这种分类的哲学基础是基于班固所著的一世纪史书《汉书》。班固在其《艺文志》中表明,此类别文本的传播方式是巷议,并由稗官(即小官吏)记录下来[7]。到了明朝,小说发展为独特的文学体裁,有自身的风格惯例,通常译作“(长篇)小说”。这一发展,加上目录学家坚持将野史分类为小说,引发了对于野史性质的困惑,并导致明清读者和现代历史学家都很不满[8]。
尽管文本细读和精细分析似乎在风格上将野史与官方历史写作(即正史)归为一类,但有时还是很难评价它们同小说的关系,尤其在边缘个案里[9]。小说的巨大数量和当时出版的野史的数量进一步阻碍了对这一关系的研究。明清两朝写出的野史即使没有上千也有成百。单个阅读每部作品,学者们能够了解具体作品的风格,但很难形成综合的概括性描述。
理解不同文体的中文文本间的关系、对导致差异的部分做语法分析,这很重要。我们到底能不能略为严谨地理解小说、野史和正史(official histories)间的相对差异?初步考察下,小说和正史的原型范例(archytypical examples)看起来往往迥然不同,风格亦无关联。但是,在正史的虚构散文(fictional prose)和传记章节间存在历史和风格关系,鲁晓鹏等学者已经指出过[10]。定量分析能让我们理解纯然虚构和非常历史的写作这两极间广阔的中间地带,通过量化作品间差异的性质让看起来非常不同的作品种类彼此一致。
本文用准历史文本数字转录本的词汇频率列表进行统计学和线性代数分析,定位不同文体文本间相互关系。虽然明清以来准历史文本的综合样本尚未数字化,但是使用现存数字作品做分析也能让我有效探索许多准历史文体风格差异的性质。这一分析针对的是内容和文体对风格的联合影响。
我使用计量文体学分析(stylometric analysis)来可视化文献间关系,突出虚构文本和历史文本间的相似与不同。通过量化分析数字文本,我能判断文本内部证据是否提示了野史本身构成有内聚力的(cohesive)范畴,并将它们同其他历史及准历史叙述的关系视觉化。它还有助于理解在何种程度上历史内容能预测风格。
我发现,在风格上模仿正史的野史与文言文本密切相关,经常使用更为正式的语言结构[11]。本文第一部分,我认为定量聚类分析(quantitative cluster analysis)能清楚区分野史、小说和戏剧。我将这一分析扩展到论文后半部分,研究词汇特征对这些风格关系的贡献。这一分析表明,正史、野史和小说沿连续的梯度变化曲线(gradient)落下,通过特定关键术语变量产生几个维度,由此确定曲线,这些术语同明清时期文言与白话的对比密切相关。此处出现了渐变而非两极间的截然区分,这很重要。
语料库(Corpora)
本研究中我用了三个相关语料库。第一个是包含14个文本的小型语料库,文本选择基于其对明清文学研究的一般适应性,以及其中很多作品起到准历史的作用。我选择了元末明初最著名的四部小说:《水浒传》《三国演义》《西游记》《金瓶梅词话》。还选了明末清初的四部剧本:《清忠谱》《桃花扇》《琵琶记》和《牡丹亭》,前面两部都是专注明末清初历史事件的准历史,因此相关,后两部则是此种文体的名篇。我还收入了一部文言小说《国色天香》,一部白话准历史小说《樵史通俗演义》。另有四部明朝野史:《万历野获编》《皇明本纪》《皇明盛事述》以及《野记》。这些文本并不能有意义地代表准历史。相反,这代表了理解这些艰深文本这一更为宏大的项目的谦卑开端。对数本准历史和非准历史(non- quasi-historical)文本的浅探,在评价明清文本同源性(homologies)、确认内容或文体是否预示了风格上迈出了第一步[12]。
接着我将范围扩大到126部作品,多数取自“古登堡计划”和其他网络资源,以论证野史普遍存在的聚类(cluster)倾向[13]。最后我用了一个大型语料库,包括524部小说、演义(historical romances)、野史和正史,共计约54万页[14]。最后这个语料库包含了足够文本,文体也足够精炼,可有力窥见作品间的风格关系。虽然其中大部分作品著于明清两朝,但也有几部出自更早或更晚的年代。尽管只是明清中国文学生产的一小部分,这些作品也体现了进入全文本数字分析的起步[15]。
方法(Methods)
本文中大部分分析基于用向量空间模式(vector space model)[16]反映文献。我用等级聚类分析(hierarchical cluster analysis,HCA)和主成分分析(principal component analysis, PCA)来分析文本间关系。这些技术有许多已广泛应用于语言学语料库分析和作者归属(authorship attribution)研究[17]。这两种探索方法提供了根据文献内在词汇来对文本做聚类的方式。J. H. 沃德(J. H. Ward)开发了一种等级聚类算法,我用来绘制以相似分值(similarity scores)为基础的文本关系树状图(dendrogram)。使用相似词汇的密切相关的文本在“词汇空间”(vocabulary space)互相靠近。沃德的算法将最相似的文本以词汇差异大小群集在树状图分支(branches)上,群集间有连接。借自线性代数的主成分分析提供了补充方法。这个技巧用于数据集内方差(variance)。它创建出新的虚坐标轴,文本投影其中,本质上将多维度(a high number of dimensions)简化为两个维度,可绘制在一张纸上[18]。用这两种探索分析技巧,可以将文本在风格上的不同关联方式视觉化。
本研究的核心是用词汇频率列表完成的,列表通过给文件标记字符串(tokenizing)以并计算字符频率(token frequency)生成。字符基本上都是单词,但也可能是任意一段文本,包括标点或字母[19]。但是,单词(在中文文本分析的语境中就是“词”)对文本风格测量之精确令人惊讶,即使拿走句法和语境也是如此[20]。虽然词汇频率表是出色的工具,它也有其缺陷。史蒂芬·格里斯(Stefan Gries)警告过:“它们预设语言学家(以及/或者他的电脑程序)对于何为单词有个定义,并且其他语言学家(及其电脑程序)也了解这一定义。”[21]
在中文里,要把文件转化为可计数单位是个很大的问题,因为文本缺乏自然的分隔符(delimiter)。[22]在处理未经标点的前现代作品时,问题更复杂。有些情况下,理解句子何时起止都能引发争论。这就导致如果不直接阅读,这语言便难以精确分析语句,尽管也并非不可能。幸运的是,在文言文及白话文里,一元语法(1-gram,或者“字”)通常都是独立的意义单位。分析一元语法构成了我大多数分析的基础。N元语法(N-grams)提供了对风格的有价值的测量,在作者归因算法中也显示出很大潜力[23]。
必须小心考虑最常见字符的理想数量。克里斯托弗·薛赫(Christof Schöch)发现存在一个转折点:当最常见字符数增加时,群集从最能反映作者身份转移为更能反映文体[24]。薛赫研究的是法文文本,这个转折点在大约750个常见词附近,虽然其他学者发现的有效数字不同[25]。他发现最常见的字符向量中的作者身份信号非常强,即使语料库中超过一千个最常见单词被分析时亦然[26]。学者们必须根据具体情况来评估最佳方式。高频临界值(top frequency threshold)与作者身份或文体探测之间的关系也依赖于写就文本的语言:在中文里,文体对风格的影响很大,常会模糊作者身份信号。
等级聚类分析:起始
等级聚类分析让人得以初窥14部明清文本在风格上如何相互关联。在图1中,无根树状图展示了结果。一目了然,每个文本中取出的矢量往往与同一作品中的其他矢量群集得很近并形成分化体(clade),即全都落在树状图同一个分支上的密切相关的文本组。相似文体的文本形成下一个最高位(next highest order)聚类。
《水浒传》与《金瓶梅》之间的关系验证了用此种方法作为文本关系衡量标准的有效性。三个《金瓶梅》的向量落在《金瓶梅》分化体之外,却不偏不倚落在《水浒传》分化体内。这非常引人注目,因为这些向量反映的是《金瓶梅》前三节万个一元语法片段。《金瓶梅》这个片段的大部分语句几乎一字不差地取自《水浒传》。具体而言都取自描述武松的冒险经历的章回。
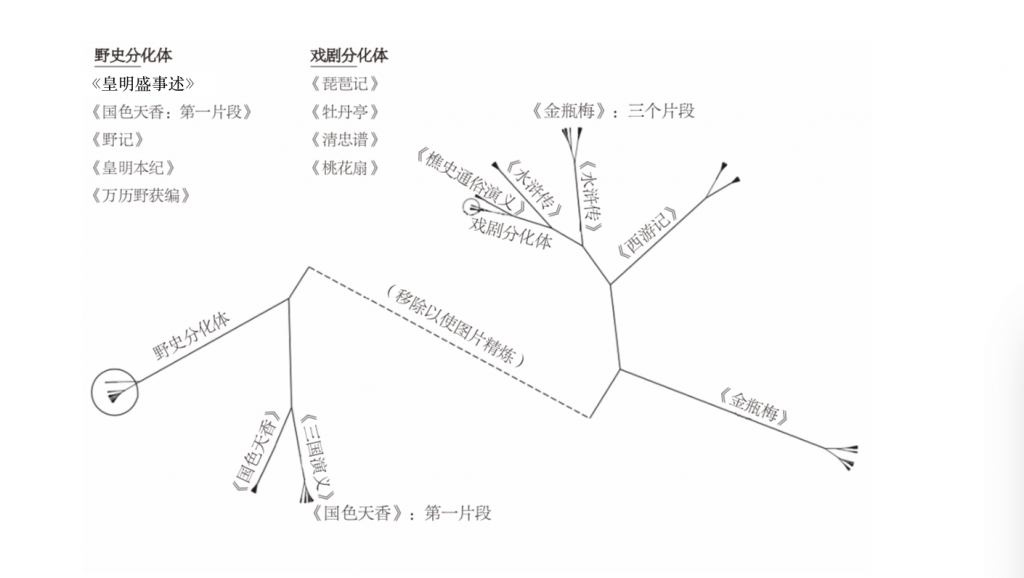
注:野史全部落在单独一个分化体上,戏剧也是。《水浒传》分裂到两个分化体。《金瓶梅》有几个片段看起来在《水浒传》的片段里。更偏文言的文本落在图左侧,右侧的更偏白话。
这个图还指向小说和野史间的偏离(divergence)。一侧是文言,历史文本为主。所有野史都群集在这一侧,还有《国色天香》和《三国演义》这两本小说。另外,所有野史都落在这一侧并簇拥在同一个分化体上。《皇明盛事述》与其他野史的关系最远,《万历野获编》落在两个小分化体上,另外两部野史落在附近。
文言的《国色天香》与野史的接近表明,野史的语言与古典小说的语言紧密相关。《三国演义》与这些作品如此密切相关也并不令人惊异。它从内容(主要关注历史)和语言来说都很相似,语言比其他一些小说更正式[27]。
白话作品主宰了树状图另一侧。不过,与图表文言一侧的作品相比,此处的作品彼此之间的关系更远;《金瓶梅》和《西游记》都相对独立于其他白话作品。不过它们与野史的关系比它们与附近其他白话作品来说要远得多。
剧本《桃花扇》《清忠谱》《琵琶记》和《牡丹亭》一定程度上有野史中发现的那种同源性,尽管内容差异显著。这似乎表明,文体对这些文本如何聚类起到了重要作用。这些剧本与《樵史通俗演义》间的密切关系有点让人惊讶。
这组样本里的同源性大多似乎不太可能来自历史题材本身。注意,《樵史通俗演义》《桃花扇》和《清忠谱》都是有关明末清初历史主题的作品,但都落在距野史和文言小说颇远处。另外,所有剧本聚类得很近,表明历史与非历史不是这个层面分析的决定性因素。很可能影响因子分等级的因素有:首先是语言风格,因为其他这些作品更偏白话;然后是文体。树状图上这些作品挨得很近,也许暗示了可能正在发生以内容为基础的,第三个层面的群集。《樵史通俗演义》和历史剧本都包含相似的历史内容,建立在明清交替时期或之前三十年的事件基础上[28]。
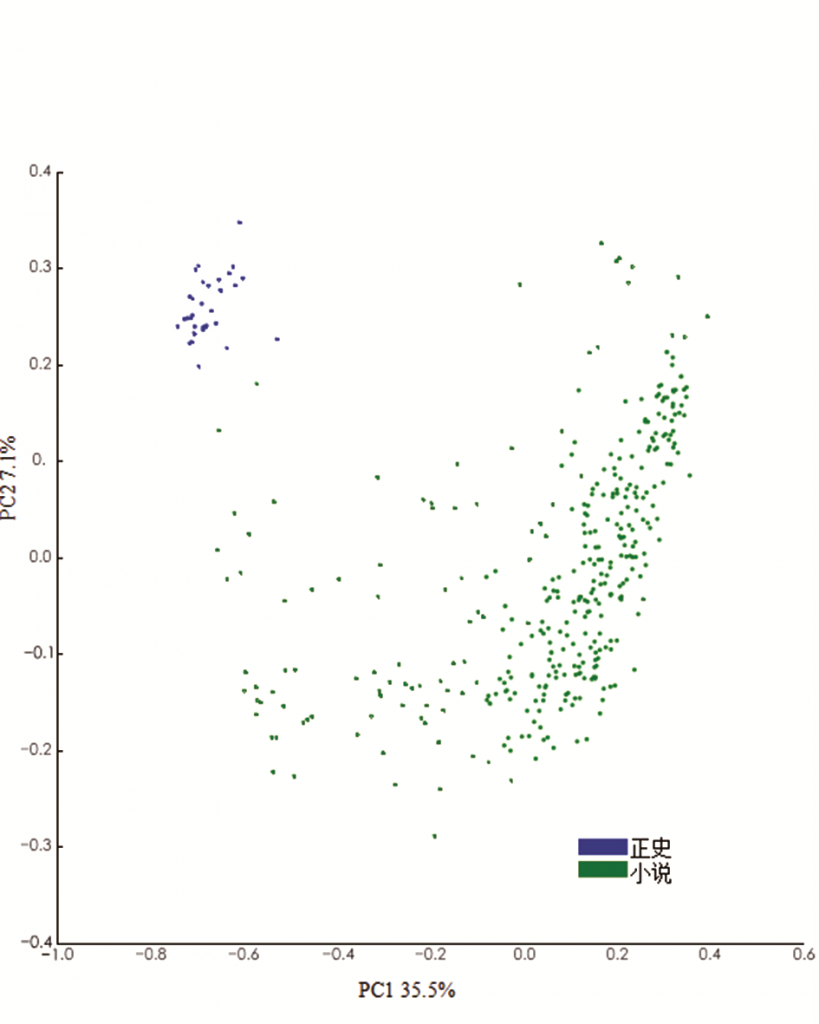
四部野史包含的一元语法频率与文言作品中的一元语法频率密切相关。那么,它们与一部正史间的关系有多近?第二个聚类分析将篇幅很长的《明史》纳入其中,回答了这个问题。图2表明了分析结果,但删除了树状图中包含白话作品的一侧,这侧和图1的区别不大[29]。野史同《明史》片段相当接近,几乎表明这些野史也以某种方式被纳入了《明史》。代表《明史》的向量在树状图中比其他作品更为分散。可能因为它包含许多主题和风格各异的片段,而且由多位官方学者合作撰写。小说略为独立于历史作品(虽然《国色天香》看起来与《万历野获编》的一部分密切相关)。
126部完整文本的等级聚类分析
到这时为止我用文本片段作为量规,判断这些作品内在组成部分之间的关系[30]。等级聚类分析提供了各种作品间比较的基础,突出了一些有趣的关系。但是聚类分析能在何种程度上辨别一部作品的文体特征?这里所说的作品是野史。野史的特征是否足够同源、能实现这样的辨别?如果只看四部作品,野史看起来是否依然那样有内聚性(cohesive)?

注:用了100个最常见的字,包括《明史》。《明史》和野史间有很近的关系。
如果不将作品切分为万个字符的切片,而是不计长度地使用整部作品,会怎样?这么做能够视觉化更大数量的单部作品,不会产生无法辨识的图像;如果切分,各切片的数量将达到数千个。同时分析不同文体的多部作品就可以为野史如何与其他作品相关提供更多信息。使用整部作品的劣势在于内在组成部分间的关系不再显明。还需要将数据标准化,保证长作品不会压倒短作品。有几种数据标准化的方法,包括以每万字符发生次数为基础为每个字符指定分值[31]。
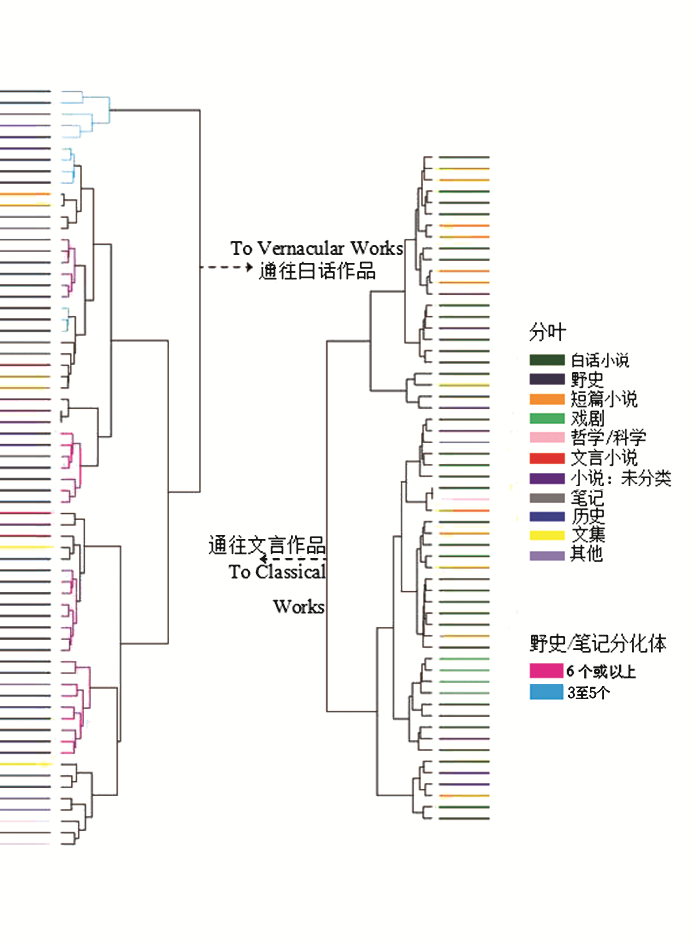
注:白话小说都出现在树状图右侧,文言小说出现在左侧。右侧没有野史出现。多数野史与其他野史群集很近,偶尔被正史和笔记打断。这些作品占据的分化体用洋红色(至少含有6部野史或笔记的分化体)和蓝绿色(至少含3部的分化体)表示。注意,两个正史分化体都和野史群集在一起。
图3是126部不同的全本作品的有根树状图。通过计算每千字中每个N元语法发生次数而让数据标准化。我用语料库中的两百个最常见字符来聚类作品[32]。
图3清楚显示了在其他树状图中存在的白话和文言作品间的大量分隔(division)。野史形成了几个非常有内聚性的聚类,只被一部笔记、几部未分类小说和两部正史打断。白话小说显示出相似的彼此聚类的趋向,剧本则紧凑在一起。分布最广的作品是短篇小说,并以语言正式性(language formality)为基础自我分隔。虽然分隔并非完美,但文本大致沿着文体线(generic line)群集。
这些树状图让我们能以新方式探索准历史。其分组一直以文体为基础,分组方式表明了野史和其他准历史的中心差异是语言风格。此外还提供证据表明野史和白话小说非常不同。此处,内容确实像是影响了结果。其中某些文本有几乎完全相同的内容,但语域不同,例如:关于宦官魏忠贤(1568-1627)的小说落在右侧(和其他白话小说一起),野史落在左侧(和其他野史一起)。
加深对虚构/历史风格梯度的理解
似乎很清楚,野史聚类靠近文言文本,远离白话小说。但这一关系(或缺乏这一关系)的本质是什么?野史是否被合理猜测为对正史的威胁或与虚构散文不一样?之前使用的小型数据集难以得出概括性结论,因此我转向一个更大型的中文文本语料库,分析明清时期虚构、半虚构/半历史和历史作品间的风格关系。以下的分析中,我考察了34部正史(2,929个一万字符片段),365部小说(5,631个片段),57部野史(347个片段),68部演义(历史题材小说,1,731个片段)[33]。多数明清文本每页有140到280字[34],也就是说一个万字符片段反映了35到70页文本,其结果是一个约50万页的语料库。除了大部分正史和一半野史,大多数文本都写于明清两朝[35]。我的分析中没有计入剧本,因为这些文本的风格惯例多少让它们接近其他作品的散文风格[36]。
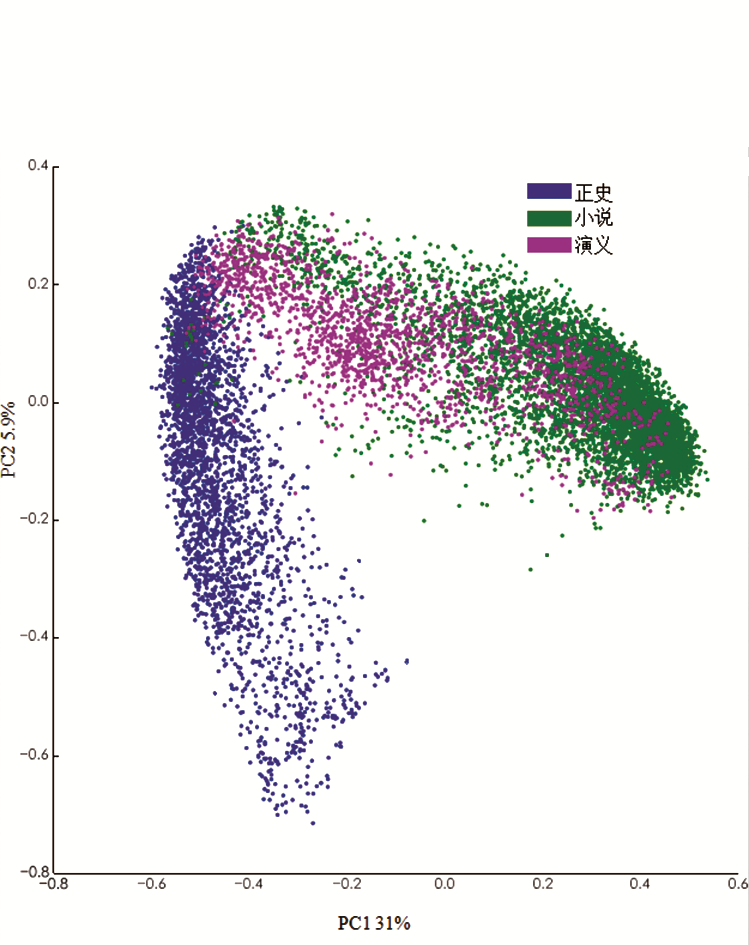
图4的聚类分析追随之前看到的趋势。最大的分离还是沿着文言/白话这条线,显示出清晰的文言与白话的对立(polarity)。所有正史都在左边,最左边的分化体几乎包含所有正史和许多野史。有些文言小说出现在树状图左边,与正史分开群集。演义让局面复杂化了,有些融入右侧的小说分化体,而其他的位于历史编纂文献之中。主要由文言写成的野史与正史关系最为密切,但也显示出与演义的某种亲和性[37]。这种混合表明,历史性内容导致虚构文本同历史著作更近地群集。在某种程度上,历史内容看起来能预测一部作品中语言的类别。探究这种明显混合的本质要求以主成分分析做进一步研究:这是风格的持续连接(bridging)还是严格的两分法(dichotomy)?历史内容究竟如何影响风格?
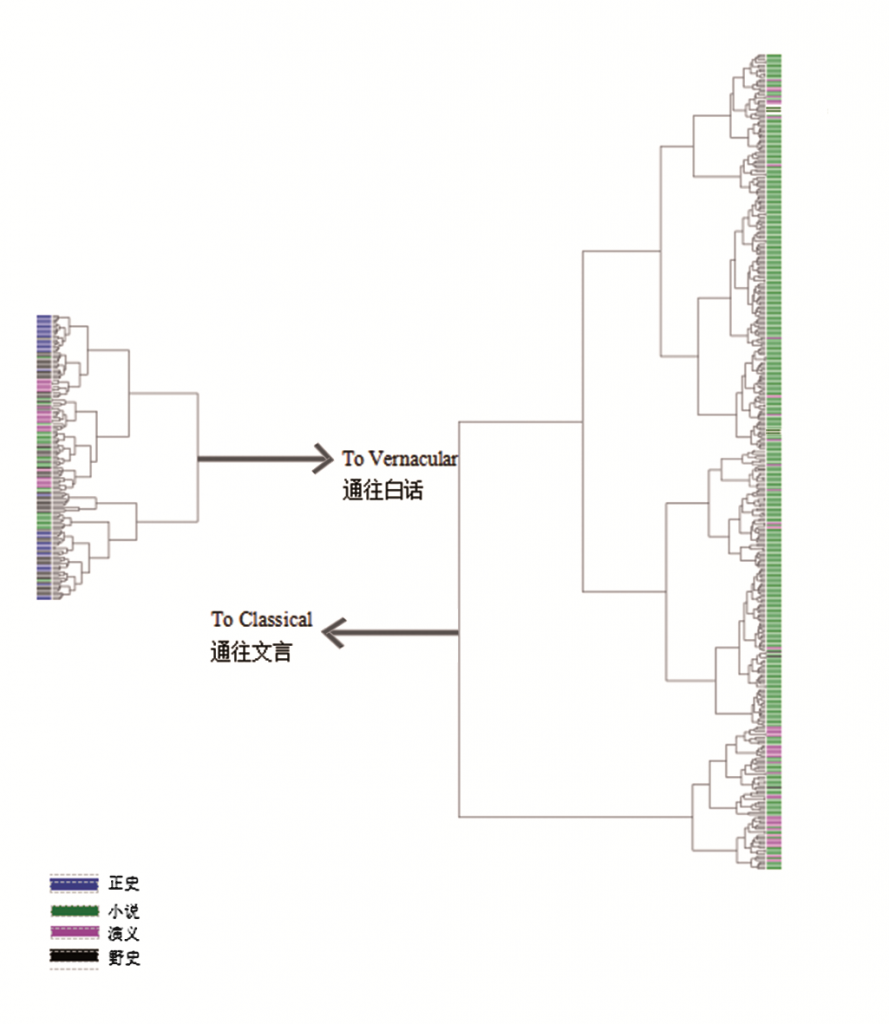
注:文本并未分为等长片段。这个聚类分析和之前的例子一样明显以文言/白话为基础分隔。树状图左侧少数几部小说都是文言,右侧有小说和许多演义及少量野史。历史和非官方历史群集在一起,只有几处交织着演义和高度文言的小说。
主成分分析
野史形成了相当有内聚性的文体,与正史紧密群集并更广泛地与文言作品聚类在一起。明清目录学家在野史和小说(petty talk)之间构建的密切的目录学关系似乎已是过时的诡计,这也更支持了有些人所持的有必要区分这两种文体的观点。然而,明清小说家倾向于将野史这个术语挪用到自己的书名上,加强了与当时“小说”的关联。在“文献”数据集里至少有两本小说在某些选集里归类为野史,而其他各种小说在书名里加入了野史或有关术语[38]。目录学家是如何构想文本的,以及他们想传达给普通读者的印象是什么样的,这两者间有清楚的区别。小说作者通过将野史纳入自己书名里来对付这种二分法,这方式很有趣[39]。图4白话小说中野史的群集可见若干此类例子。
等级聚类分析(HCA)为明清文本不足为奇的大面积文言/白话差异提供了新的认识。但是,要在HCA里确认这种差异的本质则依赖于对数据集构成的先验知识。主成分分析通过对数据集内部偏差做语法分析,让人对文本间关系有更清楚地理解,并揭示构成偏离的确切的词汇差异。主成分分析(PCA)没有对语料库的先验知识,但解释了文本为何这样群集。它还让我能够将文本以新方式视觉化,在计算主成分后,数据可绘制到这些主要成分上,分别作为抽象的坐标轴。关键是这让我们理解历史性修辞(historical rhetoric)对文本风格的影响有多大,偏离发生是由于某些以内容为基础的语义影响,还是历史话语(historical discourse)对语料库中非常见的词施加了影响。
为了恰当地描述历史作品和虚构作品间的偏离,我从一个应该显示明确分隔的语料库子集着手:小说和正史。图5a显示了取自正史和小说的一万个一元语法片段,将其绘制(plotted onto)到前两个主成分上。这两种文本文体间有明显不同,只有少量小说片段突入正史占据的空间。这支持了前面图表里看到的现象。不过,分隔如此明确也有些出人意料。两个文体沿着线状劈理(a linear cleavage)分开,多数差异沿着第一个主成分分布,占数据集内偏差的33%。第二个主成分占所有偏差的约6%[40]。
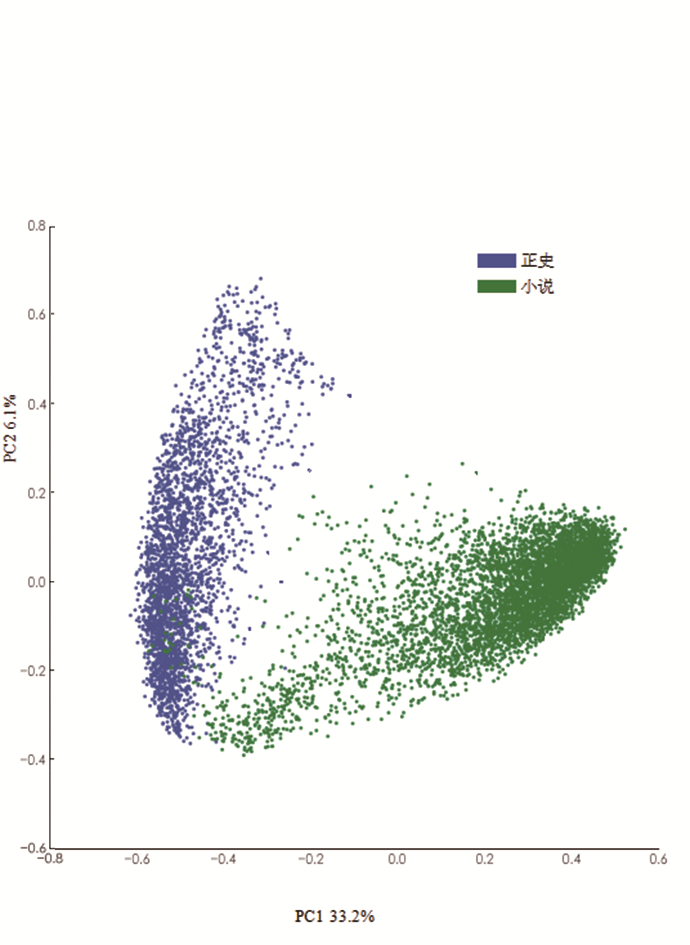
注:除了少数例外,小说和正史的文本片段在绘制时都沿第一和第二主成分聚类。少数小说片段确实侵入主要由历史占据的空间。没有历史作品进入PC空间中右侧密集的小说空间。
群集显而易见,但要恰当阐释这个PCA,需要看一张因子载荷图(loadings plot),显示的是每个变量如何影响文献在图5a的落点。图5b则增加了对主成分本质的了解。有几个问题立刻就清晰起来。第一主成分大致与文本语言的正式性相关联,也就是与文本的文言或白话程度有关。例如“之”和“的”都是从属助词(possessive particles),意思大体相同,但前者是文言词而后者是白话词[41]。第二主分量更难做语法分析,但是与时间、地理空间相关的词脱颖而出。它们将文献拖到左上象限(年year,月month,州province,南south,西west,二two,三three),这块空间完全由正史词组成。对时间性和空间的特别关注在历史里并不意外,意外的是它在区分历史著作片段和小说时能做到多少。小说和历史文献一样,通常会将事件设置在清楚的地理和时间位置中[42]。包含很多否定词(不no)、非正式语言和非正式人称代词(你you,我me,他him)的文献从主成分空间中心底部向中间偏右分布,这些作品全是小说。
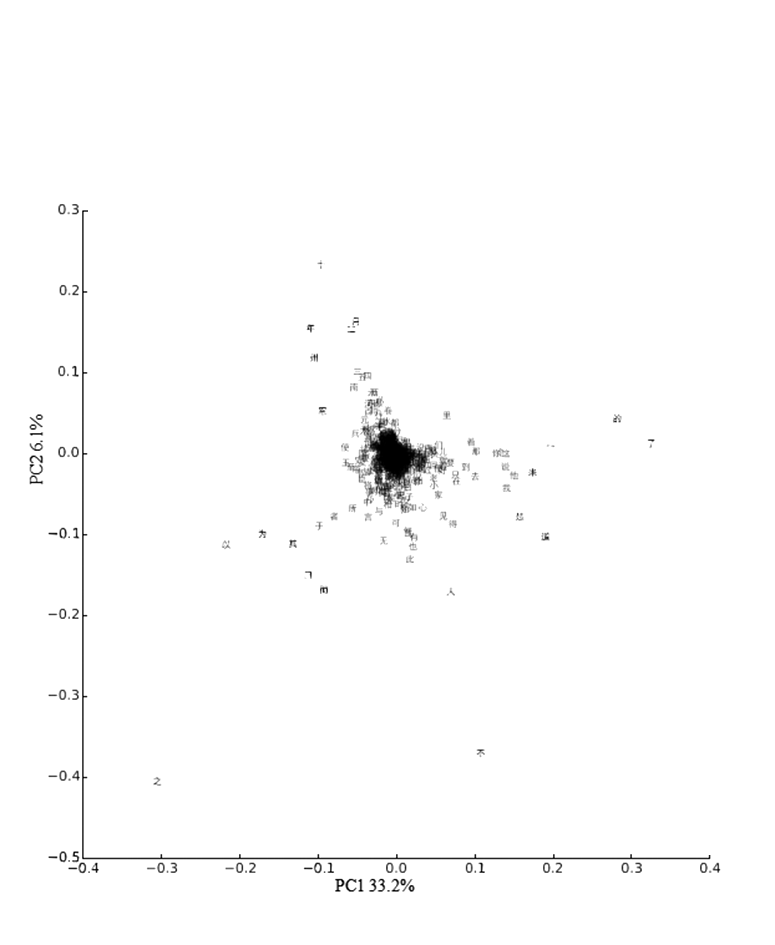
注:这个载荷图显示了变量对主分量的影响。很清楚,第一主分量与文献散文的文言或白话程度有关。左边的汉字更常用于文言作品,右边的汉字则往往在白话言语中占多数。第二主分量不那么清楚,但仍然显示出一些有趣的行为。正载荷明显与地理位置和时间有关。负载荷似乎与人与感情的关系更近。
这些主成分形成的对角线上发生了有趣的交互作用,对穿过各主成分的载荷更细致的观察提出了若干更为具体的结论。第一个成分显示出从文言到白话语言的梯度(gradient)。表1显示了沿第一主成分(PC1)的最高负载荷和正载荷[43]。
表1 沿PC1的前20个负载荷和正载荷,呈现出强烈的文言与白话的对立[44]

续表1 :

在解释了大约百分之六的偏差的第二主分量里,负载荷略为不容易诠释。“之”(possessive)和“不”(no)依然解释了许多沿着这个主分量的偏差。有些不那么有影响的负载荷可以解释为与人和内在性(interiority)有关,但这也可能是过度解释(reading too much in to them)。这种含糊并非特别意外,既然小说颇为均匀地沿这个主分量下部分布。但正载荷信息量大得多,解释了历史文本里的许多偏差,并且在时间和空间上都与历史性(historicity)密切相关。
表2沿PC2的前20个正载荷:这些载荷与数字和地理位置强相关[45]。
表2 PC2里的前20个正载荷
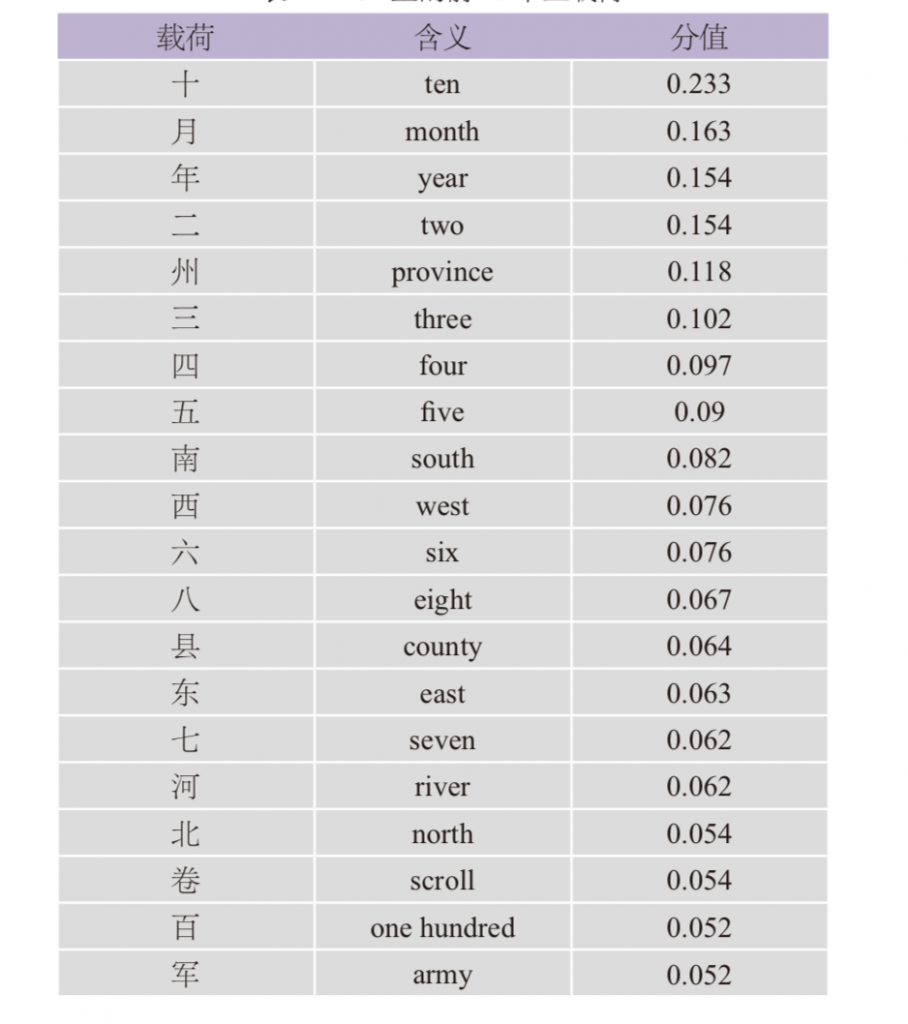
图5a左下象限有几部小说混杂到正史空间里,表明至少在某些子片段里,小说和正史可能有相似风格,我会假设这些文本多为历史题材小说。考察完整文本的PCA时这种混杂就不那么清楚,虽然它们明显群集一起,如图6所示,但其间的空间的本质模糊。
注:PC空间的形状存自图8,但此处小说混入历史空间不那么明显。这也不意外,这意味着虽然有些内部片段带有特别的相似之处,这些相似之处在考察全文时就模糊起来。第二个PC也不再被数字占据。相反,它在正向受到具有官方含义的词的严重影响。负向与人及感情模糊相关。
图6的第二个PC比上一个例子更有趣,提供了很有意思的范围,从负载荷的内在性(知to know,心heart,见tosee)到正载荷的某种历史性(军army,皇帝emperor,王king,州province)。充满数字的编年史部分的影响则减少很多。
为了进一步分析这些文本间的关系、理解其风格学,就有理由加入演义。这样就提供了纯虚构小说与历史之间风格学和内容驱动的有趣妥协。演义是对历史事件的虚构重述(fictional retelling),因此在内容上与历史相似,在修辞上与虚构作品相似。虽然许多演义以浅近的文言形式(simplified classical form)写作,但是还有许多则完全是白话。在传统意义上,区分小说和演义有点反常,因为多数目录学家认为演义是一种小说。“文献”网站的分类模式提供了容易上手的区分,有助于本分析。
图7显示了小说、演义和正史。这个空间的形状和图5a的类似,但演义非常齐整地位于小说(fiction)和正史间的边缘。它们广泛渗入小说里,少量渗入正史。这些文本看起来沿着一个在本主成分空间中显现的多维度风格梯度落下,各极分别是白话、文言、历史和虚构语言。
注:演义进入图片后,PC的整体形状相同但翻过来了。演义沿着小说占据的相同空间分布,但进一步突入了历史占据的空间。虚构的作品与历史作品间相同的线状劈理依然明显。
图8显示了这些文本的主成分空间,加入了所有在北京的文集(the Beijing collection)里确定的野史。大多数野史文献都落在由正史控制的空间里,横向沿着正史文献方向。然而有较大部分伸入演义占据的空间,还有些混杂在纯小说里。它们构成了小说文体(novelistic genre)和历史文体(historical genre)间一道明显的连接。
落在图8中间偏右小说空间最密集部分的万字片段说明了野史的复杂本质。这些片段取自两个文本:《留东外史》和《留东外史续集》。这是民国早期文本,一般被看作小说。实际上,根据其在“文献”网站上的原始分类,它们就是小说[46]。图8充分表明,野史在图上分布的方式符合其复杂的风格性质、目录学性质和文化本质。与演义一起考虑时,野史填补了纯小说和纯历史两边之间的空缺。
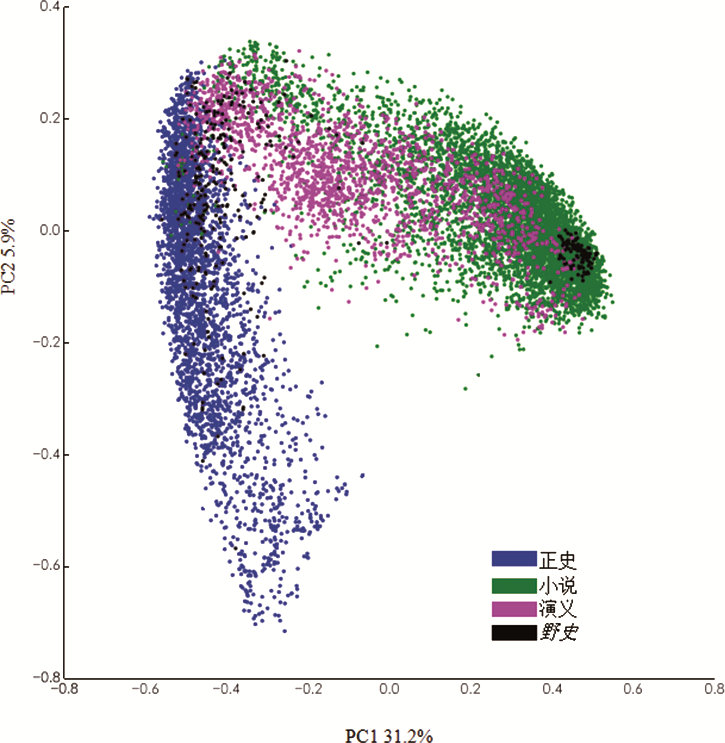
注:野史进入图片后,与正史有大量相似点,与基本由演义占据的空间相重叠,甚至有两个例子进入了右侧密集的小说空间。有趣的是那两部野史其实是伪装成野史的民国时期小说。
上述用到的语料库也产生了几处局限。许多文本落在所研究的明清时代之外,而且没有太多野史。另有个语料库可以代表野史。文献网站上历史部分有一类文本,叫作《志存记录》,收录了大量非官方历史,以及几种其他文本类型[47]。这个语料库限于明清时代写作的文本,图9有显示。这批新文本与正史和正史的演义共享了很多空间,但也伸入了白话小说空间。PC空间的整体形状显示了野史在这些文本形成的风格空间中的桥梁效应。
载荷被证明是理解这些文本间语言学关系的有效方法,不过也有其他方法可以测定哪些字(characters)区分文本最有效。用来从图8语料库里选取重要特征的线性支持向量机(linear support vector machine)提供了某些启示,尽管其中有些文本一元语法的使用有明显重叠。它发现,区分这些文本的20个最重要特征是:一(one),不(no),为(to make/to act as),之(所有格),了(动态助词),人(person),以(to use),你(you),兵(troops),军(army),十(ten),后(after),州(province),年(year),我(me/I),来(to come),王(king),生(to be born/Mr.),说(to speak),道(road)。这些特征与之前看到地穿过前两个主成分的载荷极为相似。这就强化了之前得到的结论:“正式性”和“历史性”的光谱构成了这些文本中的差异结构(structure of the differences)。同时也表明,由于特定术语的文言变体和白话变体呈负相关,做区分时通常不需要相反的同源词。
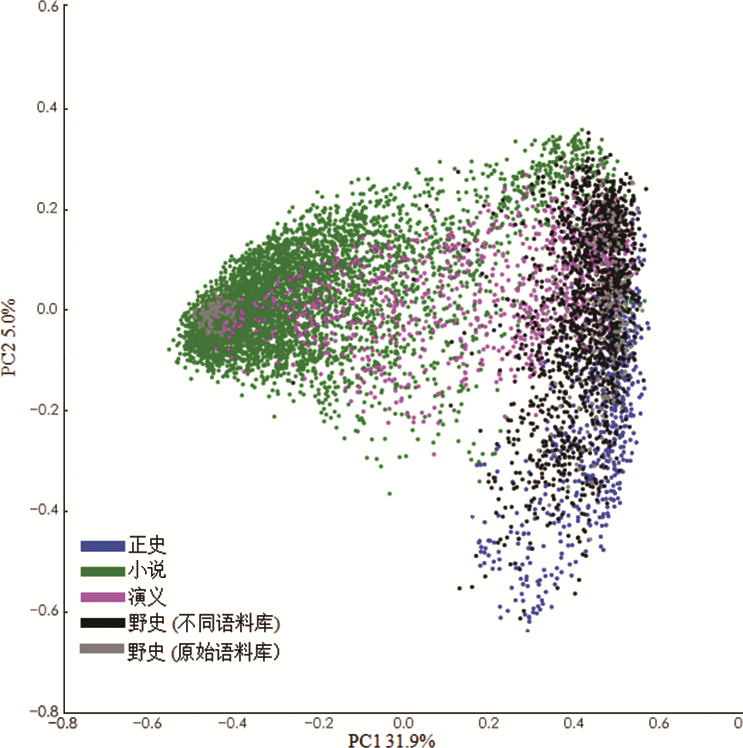
注:正史、小说、演义和选自wenxian.fanren8.com网站《志存记录》部分的文本(这部分除其他文本外还包括大量野史)。这个语料库限于明清两朝写成的文本。包括10000个一元语法片段、1000个最常见字符。形状与之前的图形状类似,但野史和正史的重叠更为明确,也较多突入虚构作品空间。
结论
等级聚类分析和主成分分析都为理解明清中国文学的虚构叙述与历史叙述间的风格关系提供了新见解。等级聚类分析表明了中文文体的文本如何自如地群集,暗示了更广泛的、由文言和白话语域定义的语言对立,这在一定程度上也是所选语料库造成的人为现象。如果它包括纯粹的诗歌作品,这种二分法可能不会出现,然而观察更宽泛的虚构和历史散文时它确实出现了。
主成分分析打破了在HCA里看到的对立,揭示了在多种语料库的前两个主成分中都很明显存在的多维度风格梯度。正史通过中间的野史和演义与小说联结[48]。这种连续性主要由文本中语言的性质解释:野史和正史一般采用文言,而小说显示出宽泛的语域,其中较大部分由相当于白话的语言写就。在历史文体中,另有一片差异区间(range of differentiation)沿着历史的/内在性梯度伸展。正史充满了具有强烈历史和地理意义的词,而小说则被某些内向的否定词、人物和限定词(limited words)轻微影响。
以上有些结论并不意外:我们早就知道小说存在于白话和文言之间的语言连续体(linguistic continuum)上,正史以非常正式的语言写作,野史是颇为正式的文本。我们现在能做的是将具体文本置于此连续体中。另外,定量分析使我们能够轻易确认并追踪目录学的例外,挑出来进一步审查。
我们确认,野史是半变动的(semi-variable)文体,风格上与官方作品混合,也伸展到小说主宰的语言领域[49]。这直接指向明清及现代围绕野史作为官方话语中边缘化的历史文本文体的讨论。野史与正史著作的同源性,以及偶尔伸入小说空间,这都是清晰易见的,强化了它不稳定的位置。野史不偏不倚落入小说空间,揭示了与野史构成成分有关的重要信息,尽管野史这个术语公认是个不稳定的概念(construct),容易成为错误归类或小说作者有意识的选择,以便将自己的故事纳入更广的历史/虚构话语框架内。
更关键的是,定量分析揭示出,历史内容只略微地、而非决定性地预示风格。回想图3,包含几乎相同历史内容的有关魏忠贤的文本根据文体群集在图片不同侧。然而在研究大型文本系统时,野史和白话小说的明显二分法就打破了。在具体案例中似乎显而易见的事并非宏观层面特征的精确描绘。有趣的是,即使分析中带有强烈历史语义的词汇很有限,历史的风格影响依然有效[50]。PCA载荷表明,语义上重要的历史术语在区分文本上起到了作用,但其他更基础的词同样重要。这意味着历史话语在非常基础的层面上对文本语言的使用施加了结构性影响。
附录I:汉语词语切分(Word Segmentation in Chinese)
用算法分析中文文本的词界(word boundary)是计算科学家和语言学家积极研究的领域。虽然研究这一问题的多数学者的主要目标集中于机器翻译和文本语音转换软件,但对文学学者来说,影响也是重大的[51]。但系统虽然越来越复杂,却很少有算法能够超过95%精确度[52]。
早在1990年,统计学家和语言学家已经在开发基于概率的方法划分中文词。1990年,理查德·斯普罗特(Richard Sproat)和石基琳(Chilin Shi)通过研究中文报纸语料库中的字的关联频率(frequency of zi association),达成了相当不错的边界识别率[53]。他们又根据最强正相关把“字”组成“词”。在斯普罗特的测试中,他们能将约90%的字正确分组[54]。
斯普罗特的研究出版以来,在词语切分上已有许多进展。最新的方法利用监督式机器学习,从程序上生成规则以更精确地找到词界[55]。其他方法使用最大匹配(maximum matching)算法,靠的是将文本中的“词”与手写规则(hand written rules)指示的现有词汇表相匹配[56]。看起来这些机器学习为基础的算法显示了最大的潜力,但它们经常需要用预先做过语法分析的文本来做广泛训练集(training sets)。最近人们在无须训练集的词语切分技术方面有些进展。对那些较冷门时期的文学研究者来说,这些无人监督的算法很有希望[57]。
其中有些方法现在普通学者也能得到。斯坦福大学分词系统(Stanford Word Segment)是公众可获得的机器学习分词系统,既考虑了词汇特征也考虑了词出现的语境[58]。它能利用以下两个训练集中任意一个:宾夕法尼亚大学的中文树库(Penn Chinese Treebank, CTB)和北京大学分词标准(Peking University Standard, PKU)。前者是其中较大的一个,人工切分(manually segmented),包含词性标志[59]。斯坦福系统对现代汉语有效[60],但分析文言文只有少数时候精确。
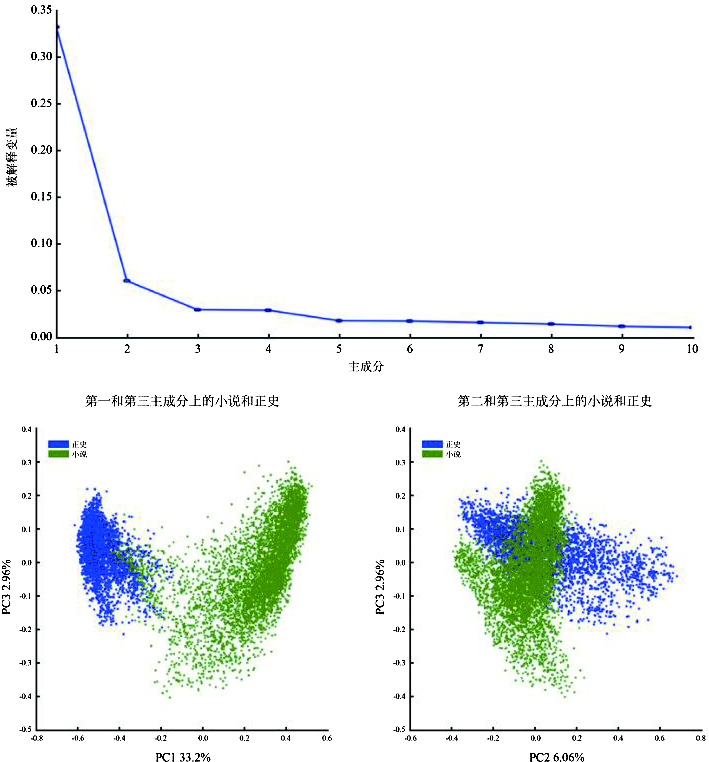
注:这个图显示了图5a和5b所用的数据集里前十个成分中的被解释变量(explained variance)。左下附图PC1和PC3:PC3只解释了数据集内变量的约百分之三,解释的内容很少。右下附图PC2和PC3:PC2和PC3一起也未能很好地解释这些文本间关系。
用汉字N元语法做汉字的字符切分有利有弊,与词“words”或单词的N元语法相反。用N元语法做字符化分词的主要好处是比较确定的,虽然还不能立刻看出来用计算机算法来分析古代汉语文本能有多精确。古汉语的“字”和“词”缺乏明确区分[61],这意味着N元语法分析很大程度上消除了由于缺乏良好的古汉语语法分析程序所带来的问题。不过,一元语法为基础的分析常常将语言分解得太过。古汉语里大多数词都是单字,但也有复合字存在[62]。二元和三元语法分析为语境增添了信息,但随着N的增加,对数据做语法分析很快成为一个问题[63]。
—————————————————————————————————————————————————————–
Fiction and History: Polarity and Stylistic Gradience in Late Imperial Chinese Literature
Paul Vierthaler
Abstract: Yeshi and other quasi-historical texts, in spite of their late Imperial popularity, remain poorly understood as a result of a lack of attention from literary scholars. While close analysis seems to stylistically align yeshi with official historical writings, it is sometimes difficult to evaluate their relationship with xiaoshuo. Investigation into this relationship is further hampered by the number of yeshi published at the time, as well as the large number of novels. This article uses statistical and linear algebraic analysis of term frequency lists calculated from digitized transcripts of quasi-historical texts to situate texts of various genres in relation with one another, and uses stylometric analysis to visualize the relationships between documents in a manner that highlights the similarities and differences between fictional and historical texts. By quantitatively analyzing digitized texts, we can judge whether internal textual evidence suggests if yeshi themselves form a cohesive category, and visualize their relationship with other historical and semi-fictional narratives. It also offers insight into the extent to which historical content is predictive of style. The first portion of this paper shows that quantitative cluster analysis can clearly distinguish yeshi, novels, and dramas, the analysis of which is extended in the second half of this paper to explore how lexical features contribute to these stylistic relationships. This analysis shows that official histories, yeshi, and novels fall along a continuous gradient that is defined along several dimensions by the variable use of certain key terms that are strongly correlated with classical versus vernacular uses of late Imperial Chinese.Keywords: Yeshi; Quasi-historical Texts; Fiction; Stylometry; Quantitative Cluster Analysis
—————————————————————————————————————————————————————–
编 辑 | 姜文涛
注释:
*本文的数字分析使用的脚本是我用Anaconda distribution forPython 3写的,用到NumPy, Scikit-Learn, SciPy,Pandas和Matplotlib, 有些分析最初是用Stylo R Package; Matplotlib:J. D. Hunter,“Matplotlib: A 2D Graphics Environment,”Computing in Science& Engineering, vol. 9, no. 3, 2007, pp. 90-95; Numpy: Stéfan van derWalt, S. Chris Colbert and Gael Varoquaux,“The NumPy Array: A Structure for Efficient NumericalComputation,”Computing in Science & Engineering, vol. 13, no. 2,2011, pp. 22-30; Pandas: Wes McKinney,“Data Structures for StatisticalComputing in Python,”Proceedings of the 9th Python in Science Conference,2010, pp. 51-56; Scikit-Learn: Fabian Pedregosa, Gael Varoquaux, Alexandre Gramfort, Vincent Michel, BertrandThirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss,Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, MatthieuBrucher, Matthieu Perrot, Édouard Duchesnay,“Scikit-learn: Machine Learning inPython,”Journal of Machine Learning Research, vol. 12, 2011, pp.2825-2830; Scipy: E. Jones, E. Oliphant, P. peterson, et al., SciPy: OpenSource Scientific Tools for Python, 2001, http://www.scipy.org/; R: R CoreTeam (2013)“. R: A Language and environment for statistical computing,”R Foundationfor Statistical Computing, Vienna, Austria, http://www.R-project.org/;Stylo: Eder, Maciej, Jan Rybicki and Mike Kestemont,“Stylometry with R: A Packagefor Computaitonal Text Analysis,”R Journal , vol. 8, no. 1, 2016, pp.107-121。
[1]这些作品主要与经朝廷审查过的“正史”相对,朝廷对历史写作严加管控。历史往往被认为是一项重要任务,“为官员而写,由官员来写”。EndymionWilkinson, Chinese History: A Manual , Cambridge: Harvard UniversityPress, 2000.
[2]王德威曾经研究过,晚明有关近期事件的小说如何构成“关于小说作为记录历史清晰度的方式的复兴概念”。David Der-Wei Wang, The Monster that is History:History, Violence, and Fictional Writing in Twentieth- century China, Berkeley:University of California Press, 2004, pp. 201. Han Li 也在她的研究中广泛探讨过这些小说。参见Han Li“, News, History, and‘Fictionon Current Events’: Novels on Suppressing the Chuang Rebellion,”Ming Studies,2012, pp. 56-75。此种对历史性想象的影响是我博士论文的焦点。值得注意的是,宦官魏忠贤(1568-1627)死后,其形象如何在不同文本文体中嬗变。Paul Vierthaler, Quasi-historiesand Public Knowledge: A Social History of Late Ming and Early Qing UnofficialHistorical Narratives, PhD dissertation, Yale University, 2014, chapter 1.
[3]Fredric Jameson, ThePolitical Unconscious: Narrative as a Socially Symbolic Act, London:Routledge, 2002, p. 106.
[4]内容与文体有关,但只在次要层面上。其影响散布于风格和詹明信探讨的“社会契约”之中。
[5]车吉心、王育济:《中华野史》,济南:泰山出版社,2000年,“序言”。
[6]王世贞在《史乘考误》前言写道,“野史人臆而善失真,其征是非、削讳忌,不可废也,”理解历史事件时必须权衡依靠野史的益处与危险。王世贞:《弇山堂别集》卷20,北京:中华书局,1985年,第361页。
[7]谢国桢:《明末清初的学风》,上海:上海书店出版社,2004年,第82页。
[8]邵毅平评论过“小说”这个范畴的使用就像个“垃圾桶”,因为难以将野史这种文本分类。邵毅平、周峨:《论古典目录学的“小说”概念的非文体性质》,《复旦学报》(社会科学版)2008年第3期。
[9]正史是官方断代史,并非官方历史写作的唯一类型,但提供了多样而大量的语料库可供分析。
[10]Sheldon Lu, From Historicity to Fictionality: The Chinese Poeticsof Narrative, Stanford: Stanford University Press, 1994, p. 7.
[11]虽然这超出了文本范围,但我推断这是一种获取合法性的方式。
[12]本文使用的所有语料库都能在此找到:DataVerse: Paul Vierthaler,“LateImperial Chinese Texts: The Corpus for Fiction and History: Polarity andStylistic Gradience in Late Imperial Chinese Literature,”2016,http://dx.doi.org/10.7910/DVN/GDYFAG, Harvard Dataverse, V1。
[13]“Free e-books – ProjectGutenberg,”http://www.gutenberg.org. 2014年3月10日。本分析中使用的野史来自 wenxian.fanren8.com,该网站不包括野史这个文体标签,因此我用了电子书《中华历史全集:中华野史》部分的索引作为指引。我还使用了标题中含有野史和相关术语的历史著作。
[14]这个文本语料库还取自 wenxian.fanren8.com,这是个在线的古汉语文本集。最后一个数字还包括另外 508 个可暂时看作野史的文本(后面有更多相关论述)。
[15]帝制时代中国研究的大规模文本分析的主要障碍在于要获得高质量数据。网上有各种数字化的明清文本,但有时候很难登上去,还经常有排版错误。有些高质量全文数据库要么没有大规模明清文本集,要么不允许大量下载整部作品。考虑到语料库的规模,也很难确认抄本的准确性。还有许多命名错误的文档:在网上广泛流传的一个晚明剧本《桃花扇》的版本其实是一部清代小说,并非剧本正本。我做了一些大致的检查,以确保我这里的文本足够精确,可以开始全文分析。包括随机抽查在台北“中研院”中国文史研究所找到印刷版本。随着本领域转向更为开源的精神,获得准确数字化文本的问题可能会减少。与此一致,目前有项目正在通过众包建立高质量中文文本抄本。参见http://tenthousandrooms.yale.edu/,2015 年12月17日。
[16]概念上讲,向量空间模型将文件理解为空间里的点(或向量),空间的轴由语料库包含的词汇确定。文件中每个词的使用频率决定上述空间里的文件位置。这些模式的使用案例,参见Peter Turney and PatrickPantel“, From Frequency to Meaning: Vector Space Models of Semantics,”Journalof Artificial Intelligence Research, vol. 37, 2010, pp. 141-188。
[17]FrederickMosteller and David Wallace, Applied Bayesian and Classical Inference: TheCase of the Federalist Papers, New York: Springer-Verlag, 1984; J. F.Burrows and D. H. Craig,“Lyrical Drama and the‘Turbid Mountebanks’: Styles ofDialogue in Romantic and Renaissance Tragedy,”Computers and the Humanities, vol.28 ,1994, pp. 63-86; JNG Binongo and MWA Smith,“The Application of PrincipalComponent Analysis to Stylometry,”Literary and Linguistic Computing, vol.14, 1999, pp. 445-466.
[18]在向量包含 1,000 个最常见一元语法的情况里,可将数据集的维数从 1,000 个减到 2 个,我就能将数据视觉化。它从根本上重新定位了数据轴,以便得到结果的最佳视图。Binongo 和 Smith 认为 PCA 的行为是“对原始轴的翻译和旋转,以得到新的坐标系,其坐标轴代表了最佳拟合的连续垂直线”。Binongo, “Principal Component Analysis,”p. 459.
[19]Matthew Jockers在研究莎士比亚文体时使用的44个字符中用到了标点符号。Sarah Allison et al., “QuantitativeFormalism: An Experiment,”http://litlab.stanford.edu/Literary/LabPamphlet1.pdf,accessed on March 24, 2014, 10.
[20]Ted Underwood,“Wordcounts are Amazing,”The Stone and the Shell,February 20, 2013, http:// tedunderwood.com/2013/02/20/wordcounts-are-amazing/,accessed on March 24, 2014.
[21]Stefan Gries, QuantitativeCorpus Linguistics with R: A Practical Introduction, New York, NY:Routledge, 2009, p. 12.
[22]要了解更多,请参看分词附录“segmentation appendix”。
[23]Fuchun Peng, et al.,“LanguageIndependent Authorship Attribution using Character Level Language Models,”http://www.aclweb.org/anthology/E03-1053,accessed on December 11, 2015; 分析之前有必要进行大量文本处理。每个文件我都抛弃了标点符号和不重要的人为痕迹。有些情况下我将每部作品分为等长的 N 元语法片段,保证等长文本间都有对比。我还抛弃了剩下的不等长的部分。我最初发现这个将文本分为均一片段的技巧是在Binongo和Smith的“Principal ComponentAnalysis”里,他们通过“将这些剧本分为 5, 000 字片段(不顾实际的幕或场景区分)……”创建了一个表格。Burrows 和 Craig 使用类似方法(p. 448),将他们感兴趣的剧本分为4, 000字片段。在试图确定一部作品可疑片段的作者时,这个方法尤其有效(p. 67)。这么做,我也能将文本内部片段如何与其他作品相关联视觉化。片段的长度影响结果。文本片段越短,越可能出现小的相似处,这更可能是内容驱动的结果。文本越长,整体风格越重要,文本内的小变化也被抹平。较长的片段往往会根据已知标签更好地聚类。遇到繁体字文本时,我将文本转化为简体字。我为每个文本片段计算出一个 N 元语法频率表,以便用向量再现每个片段。每个向量包括全部 14 个文本中最常见字符的字符分值。每个向量代表 N 维空间里一个点(或一条线),其中 N 是唯一变量数(number of unique variable)。使用沃德方法的等级聚类分析在相似性度量的基础上群集了最密切相关的向量(因此也汇聚了文本)。此方法聚类向量,目标是减少群集内差异的总数量,并将最相似的向量分组在一起。 J. H. Ward,“HierarchicalGrouping to Optimize an Objective Function,”Journalof the American Statistical Association, vol. 58, no. 201, 1963, pp. 236-244. 最初评估时我测量了每个片段文本最常见字符向量间的欧几里得距离,然后将其按等级聚类。考虑到每个文本等长,我在多数分析里用了欧氏距离而非余弦相似性(cosinesimilarity)或其他量度。各种距离计算方法的讨论参见Christof Schoch,“Beyond theBlack Box, or: Understanding the Difference Between Various StatisticalDistance Measures,”The Dragonfly’s Gaze, August 3, 2012, http://dragonfly.hypotheses.org/101.Accessed on March 24, 2014。
[24]薛赫考察了最常见单词列表长度在多大程度上产生影响,他发现在使用较短的列表时,作者身份是导致聚类的主要因素。一旦越过惊人的高临界值后,文体就成了聚类的一大因素。Schoch“, Author orGenre?”
[25]MatthewJockers只需要44个就可以将大量英语小说性作品分类。Allison“,QuantitativeFormalism,”p.6.
[26]Schoch“, Author orGenre?”
[27]虽然《三国演义》常被归类为白话小说,但它包含许多文言成分。在《中国古代小说总目提要》(北京:人民文学出版社,2005年)索引里列在白话部分。Anne McLaren提到其语言时说它是“浅近文言” (simplified classical)。Anne McLaren“, Constructing New Reading Publics inLate Ming China,”Printing and Book Culture, ed. Cynthia Brokaw,Berkeley: University of California Press, 2005, p. 176. 本文后面将这部小说分类为“演义”,一种特定小说类型。
[28]除了与《金瓶梅》有关,《水浒传》还有更多趣事。它清楚地落在两个不同的分化体上。包含与《金瓶梅》有关的片段的一侧,最可能与本书第一部分一致,这部分讲述故事里好汉们是怎么上梁山的。第二片段落在截然不同的分化体上,讲述的是成群草寇的冒险。这有几种解释,有些更偏猜测。最可能的解释是叙事风格的突变,从个人轶事变为战役风格的活动。可以推测两名不同作者写的这两部分,第二位作者无法完全模仿原来的风格。这与质疑施耐庵作者身份的学术研究一致。争议集中在施耐庵是谁,会不会就是罗贯中,或者是否他俩都参与写作了这个文本。《印第安纳中国古典文学手册》编辑声称“证据排除了单个作者的可能性……”并拒绝认为施耐庵和罗贯中是作者。Jr. WilliamNienhauser, ed., The Indiana Companion to Traditional Chinese Literature,Bloomington: Indiana University Press, 1986, p. 712.
[29]我在最初的分析中没有包括《明史》,很大程度上因为它太长了;分为几个片段后,它占据了群集分析,模糊了野史群集得有多近。
[30]这个技术是我从 Burrows 和 Craig 处借用的(p. 67)。
[31]Ted Underwood描述了另一个分数标准化的可靠方法,源自尺。他主张计算一个词在文本中实际出现的次数与文本代表整个语料库时一个词出现的预期次数之间的距离。“Tech Note”,http://tedunderwood. com/tech-notes/, 2014 年 3 月 25 日。
[32]所有文本长于 1 万字符,较短文本被抛弃。Eder 提出随机样本对较短文本的作者归属有效,但此处我排除了较短作品。M. Eder“, Doessize matter? Authorship attribution, short samples, big problem, ”Literaryand Linguistic Computing, 2014, p. 29.
[33]这些文本全部来自 wenxian.fanren8.com,该网站上可随意获取许多电子版中文文本。这批文集里的 “小说”就是晚明和清朝风格惯例所理解的“小说”,不是中国历史上早得多的时期的“petty talk”。
[34]PaulVierthaler,“Analyzing Printing Trends in Late Imperial China Using LargeBibliometric Datasets,” Harvard Journal of Asiatic Studies, 2016, Figure6.
[35]野史和正史里的语言历来相似。不过不考虑这些,我后来将分析仅限定于明清作品。
[36]将剧本加入等级聚类分析显示的结果不出所料。除了几个经典例外,剧本全都群集在树状图白话侧的同一个分化体上。为了完成必要的计算,我用了Python Package Scikit-Learn执行词汇频率向量器。这个词汇频率向量器用 l2 标准化方法令结果标准化。
[37]我把一种无关文体塞入分析,这些文本往往自己聚类,远离历史和虚构类型作品(就算它们基本是散文,例如诗歌评论)。运行这些测试时,有时需要平衡输入语料库,让每个文体截取的片段数目等同。尤其是在评价此处讨论的文体之外的文体时,因为它们对主成分空间形状有很强的影响。
[38]这些术语包括外史(outer history)、逸史(hidden history)、秘史(secrete history)。
[39]进一步研究的一个有趣途径是分析这些小说的内容及其历史语境,以更好地分析他们何以做此选择。
[40]陡坡图显示出主成分阐释价值迅速下降。前三个主成分说明了很大一部分偏差,之后迅速逐渐变小至 3% 以下。参见此陡坡图的补充图,可见同样的数据沿着 PC1/PC3 和 PC2/PC3 绘制出。
[41]“之”在助词之外有多种含义,其他用法包括用作代词和动词(意思是“去”)。
[42]图表左上角的历史片段多以编年体写成,有连续的日期,这点很可能也导致了明显的区分。
[43]应宽松理解这些定义,尤其在文言文里,汉字(characters)可以有很多意思。而且要记住这些是一元语法,不是词(words)。
[44]注意有几处汉字是同源的且基本意义相同。主要差异在于左边那些往往出现于以正式汉语 / 文言写就的作品中,而右边那些往往更常见于非正式 / 白话作品中。
[45]落在第二主成分顶端的文献是正史的编年史部分,更偏散文的片段则落在更靠近小说处。
[46]要想起野史标签是从语料库之外加上去的。
[47]初步研究表明,其中许多作品是野史,那些不是野史的作品看起来风格相似。我展示了用到较少野史的初步分析,来说明语料库之间的相似性。这个语料库又为研究增加了 508 个文本,分为 1,620 个片段。
[48]我也测试了不指望在这个梯度曲线上看到的文体的文本。它们往往或者落入梯度变化曲线一侧,或者落入第二主成分靠近 0 的空间里,但是位于第一主成分更文言的一侧,处于文本混合最厉害的空间。它们一般不像正在研究的那些文本那样大量渗入其他文体中。
[49]和多数此类分析一样,有更多细节元数据的扩充语料库会明显增加结论的严谨。精确的特征选取也会增加对如何区分历史和虚构作品的理解。
[50]有个有趣的途径可以用来做进一步研究,即完全排除这些术语,再看我们是否能预测历史内容。
[51]Richard Sproat andChilin Shih,“A Statistical Method for Finding Word Boundaries in Chinese Text,”Computer Processing of Chinese & Oriental Languages, vol. 4, no. 4,1990, p. 337; Shoushan Li and Chu-Ren Huang“, Word Boundary Decision with CRFfor Chinese Word Segmentation,”23rd PacificAsia Conference on Language, Information and Computation, 2009, p. 726;Gaoqi Rao and Endong Xun,“Word Boundary Informationand Chinese Word Segmentation,”International Journal on Asian LanguageProcessing, vol. 22, no. 1, 2012, p. 16.
[52]许多方法的上限阈值在大约 90% 到 95%,例如:Sproat“, A Statistical Method,”p. 345。
[53]Sproat“, A StatisticalMethod,”p. 339.
[54]Sproat“, A StatisticalMethod,”p. 343.
[55]机器学习是种人工智能,计算程序在一个有已知特点的数据集上训练,然后从训练集中归纳规律并为训练集外的数据分类。例如,Ka Seng Leong et al.“,Chinese Word Boundaries Detection Based on Maximum Entropy Model”(论文在2007年12月3到6日的APCOM ’07上宣读);Peng Fuchun, Fangfang Fengand Andrew McCallum,“Chinese Segmentation and new Word Detection usingConditional Random Fields,” Proceedings of the 20th Annual International Conference onComputational Linguistics, 2004, article 562.
[56]Chih-Hao Tsai“, MMSEG: Aword Identification System for Mandarin Chinese Text Based on Two Variants ofthe Maximum Matching Algorithm,”http://technology.chtsai.org/mmseg/. Accessedon March 26, 2014.
[57]这个研究尚未发表,但是代表了汉语词语切分的重大进展。Ke Deng, P. K.Bol Kate J. Li and Liu J. S. (2015+) On Unsupervised Chinese Text Mining.Invited Revision by PNAS.
[58]它使用了下文描述的条件随机域(conditional random field),Huihsin Tseng et al.“, A Conditional Random FieldWord Segmenter,”Fourth SIGHAN Workshop onChinese Language, 2005. 他们额外增加了一个词法元素,与下述说明相似:Pi-ChuanChang,MichelGalleyandChrisManning“,OptimizingChineseWordSegmentationfor Machine Translation Performance,”WMT, 2008.http://nlp.stanford.edu/pubs/acl-wmt08-cws. pdf, accessed on March 24, 2014. 软件可见 http://nlp.stanford.edu/software/segmenter. shtml。我在文本分为词时用的版本 3.3.1。
[59]NianwenXue, Fu-Dong Chiou and Martha Palmer,“Building a Large Annotated ChineseCorpus,” Proceedings of the 19th International Conference on ComputationalLinguistics, Taipei, Taiwan, 2002, http:// www.cis.upenn.edu/~chinese/coling02.ps, accessed on March 26, 2014.
[60]Tseng“,A Conditional Random Field Word Segmenter,”p. 3.
[61]私人谈话,郭英德,2014 年 4 月。
[62]薛念文用“产”(toproduce)这个字为例说明。它可能在一个“词”的不同地方出现,或者本身作为一个词。Nianwen Xue“,Chinese Word Segmentation as Character Tagging,”Computation Linguistics andChinese Language Processing, vol. 8, no. 1, 2003, p. 30.
[63]甚至四元或五元语法也能生成非常稀疏的文言数据集。
原刊《数字人文》2020第2期,转载请联系授权。